

I've shipped enough AI features to know that sinking feeling when something works exactly as designed but still feels wrong.
Throughout my product career, I worked on several AI-powered features across different projects. One pattern kept repeating: we'd build something that met every specification, passed all reviews, and impressed stakeholders in demos. Then real users would start using it, and we'd discover questions we should have answered months earlier.
The most memorable example was a search and discovery feature that let users ask questions in natural language and get back either a synthesized answer or a list of ranked results. It seemed straightforward—help people find information faster without needing to know exact keywords or browse through documents. I'm choosing this example deliberately because we've seen this pattern play out publicly with Google's AI Overview feature, where the core challenge wasn't the AI's capabilities but where and how it chose to present authoritative answers. What I learned from my own version of this problem changed how I write PRDs entirely.
The question that should have come earlier
There was a phase in my life when I found myself in more than one room, across different teams and projects, having essentially the same uncomfortable conversation: why did our model decide to give this comically wrong answer to the customer? Can we make changes to the “Context” so that it covers all such hallucinations?
We had no answer—because there is none. Probabilistic systems(Gen AI) are like humans in one aspect, they can be wrong and confident at the same time. The good thing is we can manage the user experience of Gen AI systems by writing better requirements— if only we could do that to humans too!
Traditionally, our Product Requirement Documents(PRDs) defined what features should do—accept natural language queries, retrieve relevant documents, generate summaries when appropriate. But we'd never addressed how certain the system needed to be before it stopped showing options and started providing answers(the Gen AI way).
The gap was always the same: we thought about AI products in terms of what they should do, not how they should behave when uncertain. They were always confident and helpful, even when they shouldn’t have.
What I kept missing in my PRDs
Here's what the user stories for that search feature looked like:
As a user, I want to ask questions in natural language so I don't need to know exact keywords or where information is stored.
As a user, I want to get answers quickly so I can make decisions without reading through multiple documents.
As a user, I want to refine my query if the results aren't helpful.
Clean. Shippable. Approved by everyone.
What I didn't realize was that I'd bundled two fundamentally different behaviors into one feature. When the system showed ranked search results, it was being assistive—helping users navigate information while leaving interpretation to them. When it generated a summary, it was being authoritative—making judgments about what mattered and presenting a synthesized answer.
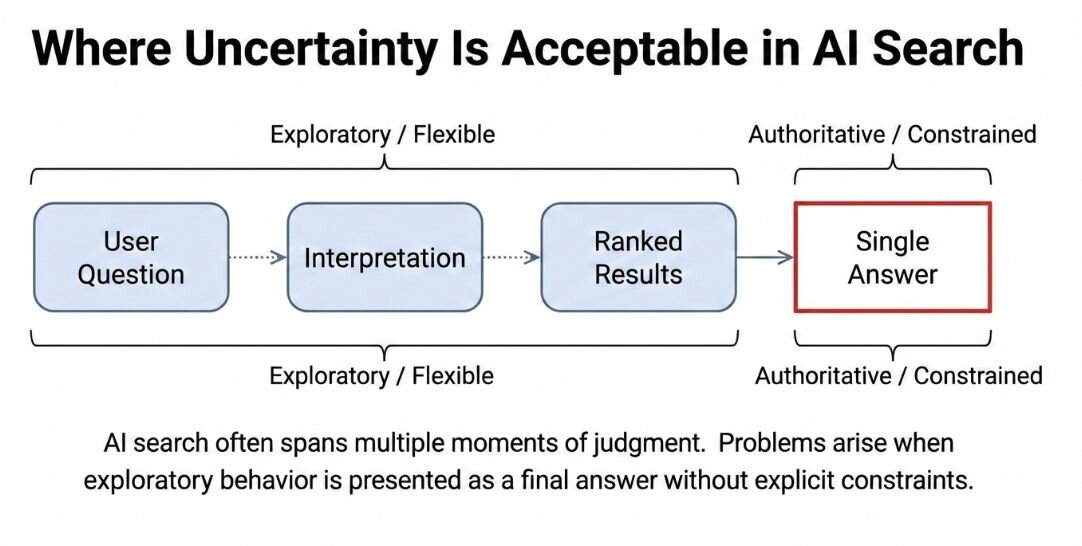
Both relied on the same probabilistic AI, but they carried completely different implications for user trust. Showing ranked results keeps uncertainty visible. Users compare options and form their own conclusions. Presenting a summary transfers interpretive responsibility from the user to the system, especially when that summary sounds confident.
I'd written a PRD that treated these as equivalent steps in a workflow. They weren't.
Decision surfaces: What I wish I'd known earlier
After wrestling with variations of this problem across multiple products, I started thinking differently about how to specify AI capabilities. I needed a way to identify the specific moments where the system makes judgments that materially affect what users see or do next.
I call these decision surfaces.
In our search feature, there were several:
- Input decision surface: When the system interpreted ambiguous questions
- Synthesis decision surface: When it ranked and filtered relevant documents
- Output decision surface: When it actually presented a synthesized answer or stayed in exploratory mode with ranked results

These weren't equivalent decisions. The last one—Gen AI versus exploration—carried the highest stakes because it determined how much interpretive authority the system claimed.
What this looks like in practice
Let me show you how I'd specify that critical decision surface now, using the search example.
The system should present a synthesized answer when the underlying sources tell a consistent story, when the information is fundamentally factual rather than requiring interpretation, when we can clearly cite the evidence used, and critically, when being slightly wrong wouldn't mislead users in consequential ways. For straightforward factual queries where all sources agree, a direct answer makes sense.
The system should default to showing ranked results when sources conflict, when important qualifiers exist that change the meaning, when the answer depends on judgment rather than retrieval, or when the stakes of error are high. For queries about policies, procedures, or anything with potential exceptions, showing ranked results lets users see the full context.
Here's what changed my thinking: this decision can't be governed by a single confidence score. A model can be highly confident while generating an answer that omits important nuances. The confidence score measures how well the model predicts the next token, not whether the information requires human judgment.
What matters is the consequence of being wrong at this specific point in the user's experience. An incomplete answer that sounds authoritative is worse than multiple options that require more effort.
How this changed my process
Once I started defining decision surfaces explicitly, the dynamics of product development shifted in ways I didn't fully anticipate.
Conversations with stakeholders became dramatically more specific. Instead of debating whether our AI was "good enough" or "ready to ship," we evaluated whether it behaved correctly at particular decision points. When someone raised a concern about the search feature, we could trace it back to the synthesis decision surface and ask whether our criteria needed adjustment. We weren't arguing about AI quality in the abstract—we were debugging specific judgment calls.
Testing became clearer because QA could validate agreed-upon behavior. For the search feature, we wrote test cases specifically for the boundary between synthesis and exploration: "Given conflicting sources, the system shows ranked results" or "Given consistent factual sources with no qualifiers, the system presents synthesis." When a test failed, it revealed genuine misalignment rather than hidden assumptions.
Design decisions gained grounding in explicit reasoning. When our designer asked "Should we show a summary or a list here?" we could answer by referring back to our decision surface criteria rather than debating what felt right in the mockup. The criteria became shared language between PM, design, and engineering.
Perhaps most importantly, risk discussions started happening during planning instead of later in the development cycle. We could ask upfront "Should the system ever synthesize policy information, given that policies often have exceptions?" and make deliberate choices about when to use synthesis versus exploration.
The AI didn't become more accurate. The product became more predictable, and that predictability is what built trust.
What I'd tell my past self
If I could go back to that search feature, here's what I'd do differently.
I'd map the decision surfaces before writing a single user story. I'd sit with the team and identify every point where the system makes a judgment that affects user behavior. For the search feature, I'd have identified that synthesis-versus-exploration decision as the highest-stakes surface and specified it explicitly before anyone wrote code.
I'd define our tolerance for uncertainty at each surface, and I'd make those definitions concrete. Instead of "show results when confidence is low," I'd write "default to ranked results for any query about policies, procedures, or decisions that might have exceptions or require context."
I'd make the criteria reviewable by the entire team, not just keep them in my head or buried in a planning doc. Decision surfaces aren't just for the PM to think about. They should be explicit enough that when engineering implements the feature, they understand not just what to build but how it should behave at critical moments.
Finally, I'd test the boundaries, not just the happy paths. Once we defined when synthesis was appropriate, I'd make sure we tested edge cases where the system should hold back. Those boundaries—where the system stays in exploratory mode despite having relevant information—matter more than perfect performance in obvious cases. That's where users lose or gain trust.
The real problem wasn't model performance
Looking back at that search feature and similar projects, I realize the AI models worked fine. They did exactly what they were trained to do. The problem was that I'd been specifying features without specifying their judgment.
AI systems rarely fail because they produce incorrect outputs. They fail because probabilistic behavior appears in parts of the experience where users expect certainty. A summary can be factually accurate but inappropriately authoritative given the nature of the information.
If you don't explicitly decide where uncertainty is acceptable, the system will make that decision for you. And it will make it implicitly, inconsistently, and often at the worst possible moment.
Decision surfaces gave me a way to make those tradeoffs visible, reviewable, and intentional before products shipped. They're the difference between impressive demos and products users actually trust.