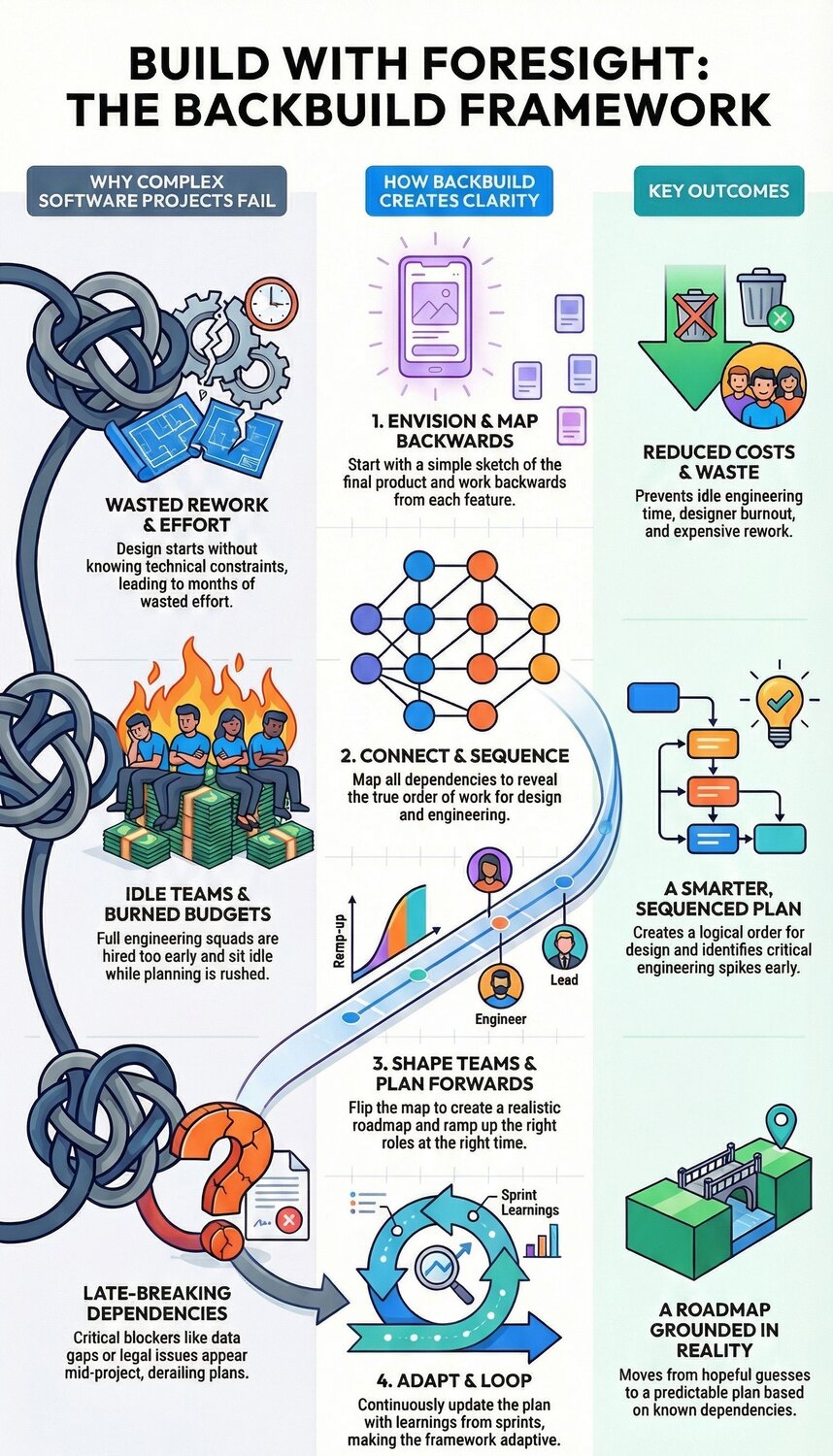
I started my career in problem-solving roles before spending 17 years in Product, usually as their first hire during a messy digital transformation.
Over the years I’d often have to work in very dysfunctional environments, which resulted in me creating a mental playbook for “survival” that gave me the confidence to take on more ambiguous work.
Project briefs, extremely light on info, were provided with only a moment’s notice before being plunged into a seemingly impossible situation to either run or fix a stalled delivery. What I discovered was that most delivery failures I got pulled into didn’t fail because of a lack of team skills, but because work was tackled in the wrong order.
This case study was the moment I started applying the approach that would later become BackBuild.
The situation
I was working for a SaaS company and I was brought in to lead them through a critical and transformational platform migration.
To do this they wanted me to drop into a newly formed team. During early discovery calls it was clear that there were capability gaps and a number of red flags that could impact the delivery.
They also had a plan to launch the new service in a matter of a few short months with an MVP backlog that had a long list of core features and journeys. The project budget was seven figures. A migration of this size, even with a strong team, would normally take 6-12 months, so there was a lot of pressure and risk from day one.
The immediate problem
Most of my team had never experienced a programme or this type or scale, so the pressure was on me to create stability and a plan for delivery fast.
The immediate problems I had were:
- Engineers were arriving imminently
- There were no validated designs or journey maps for the list of features.
- Documentation was limited
- Ways of working hadn’t been established
- The teams were new to each other.
If we had started in the normal Agile fashion, assumptions would have been made and we would have begun work without much clarity.
In my experience, for these types of complex programmes Agile is still the best tool we have for learning as we go. But it really struggles with providing foresight at scale, especially when dependencies, data and compliance constraints can derail the delivery later.
So, at that point, I had to surface what needed to be true before we committed serious build effort. I needed an approach the whole team could follow without relying on me as a single point of failure.
What we did
I brought together engineering, product, design and relevant subject matter experts from the business and we started by piecing together what the final service might look like with all of MVP features included. We then challenged the MVP based on user, customer and business value so we could ensure a realistic definition could actually be launched.
From this point, we applied a simple backwards method.
Step 1: sketching the end picture
Set aside 3hrs and together we defined the outcome we were aiming for in plain terms. It wasn’t a list of user stories, just a clear description and sketches of what would be true in the real world at the end.
Important: I realised that the end picture needed to always be provisional. We were creating a target so that we could work out the dependencies, not locking in requirements.
Step 2: working backwards
We took each remaining journey and design sketched it out so that we could all see what needed to be true in order for it to exist. We then asked one question repeatedly:
“For this to be true in production, what must already be true?”
Each answer needed to be a statement that we could test. For example:
- “There is a defined customer identifier used across systems”
- “Other systems can ingest updates through a known interface”
It was important we didn’t get bogged down in this so I limited the backwards steps to four or five deep. It was essential we didn’t disappear into detail otherwise we might fall into a Waterfall trap.
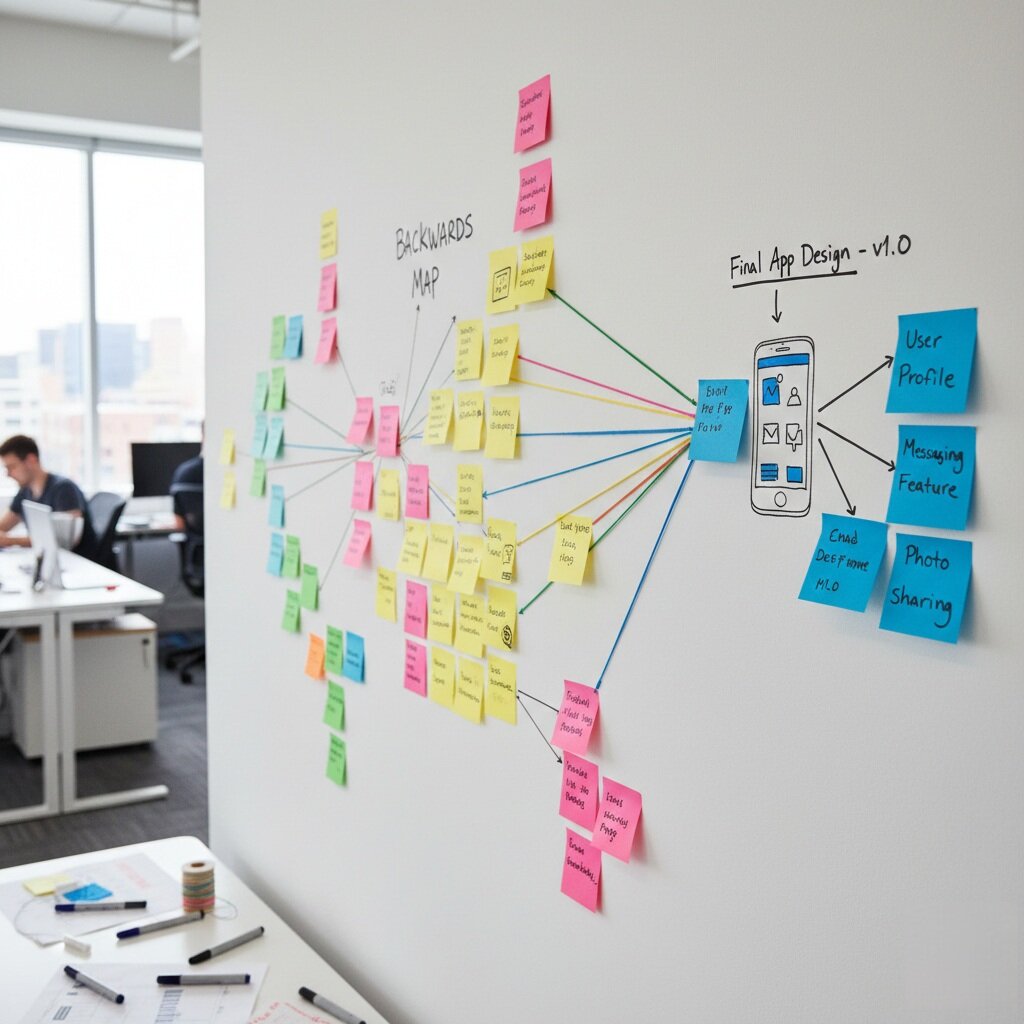
Step 3: spotting fragility
This process created a backwards map for us which identified the connections and dependencies obvious. We then created a list of fragile spots such as:
- data availability or ownership
- integration feasibility
- compliance and audit requirements
- vendor capabilities
- performance and scale
- edge cases and failure states
- user validation
These weren’t meant to be criticisms, there were risks to the project. Finding these early, I believe, made the difference between a smooth delivery and late-stage chaos.
Step 4: turning fragile spots into spikes
This is where projects usually go wrong. Teams push delivery forward and hope the unknowns are solvable when they surface.
Instead, we converted the fragile spots into engineering spikes and design validation work with clear evidence goals:
- hypothesis: what we believed to be true
- test: what will we do to prove it
- success criteria: what “proven” looked like
- owner: who owned it
- time-box: usually 1-3 days
This started to influence the sequence of work and prevented the team building upon assumptions.
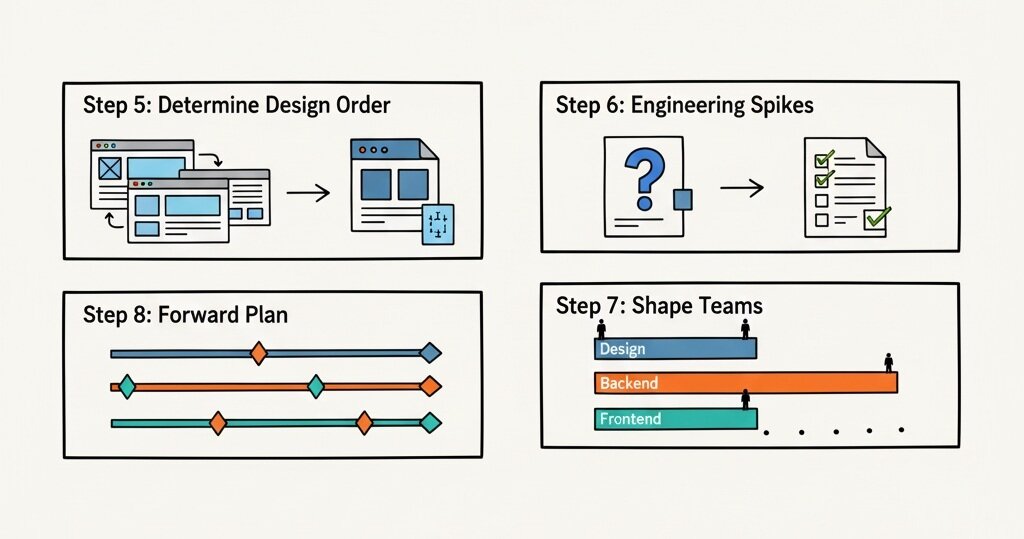
Step 5: flipping forward into a sequencing plan
This was the turning point for the team because we now had confidence to be able to start ordering the work. We had figured out the potential points of failure, what engineering spikes needed to be done first, the work order for design and which parts of engineering could safely start without creating rework.
We also learned that for this process to work properly, the map could not be forgotten. It needed to be updated with discoveries surfaced during sprints and the whole team needed to have constant access and regular reviews. This kept the plan sharp, like an architectural drawing does for a complex build.
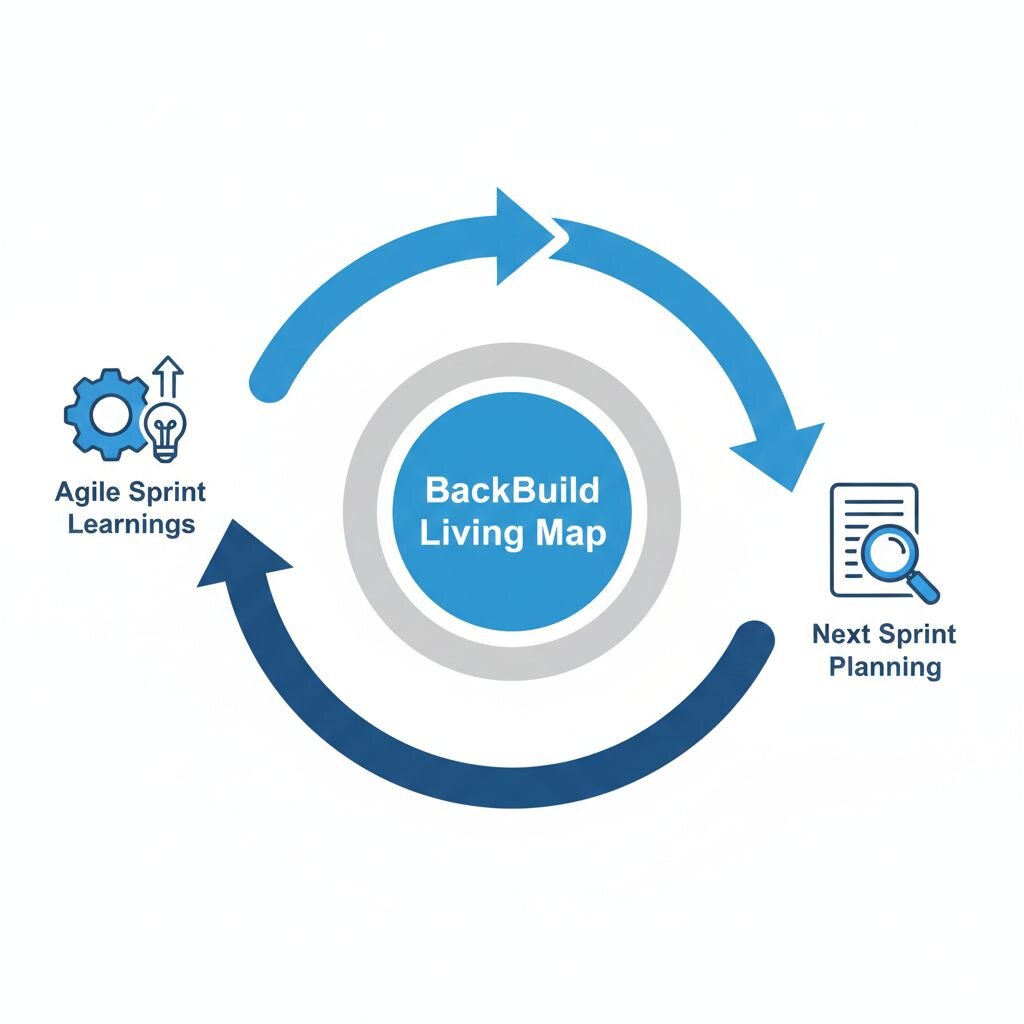
After we had been through this process, which took a couple of weeks, we were able to kick off the development properly with far fewer potential unknowns.
Having worked on many projects before where chaos was the norm, it was obvious that this approach was changing the dynamic. The process was simple and it was neatly fitting inside common ways of working.
The company launched their service with only a small delay, and without any late-stage surprises that could have caused rework. We avoided going over budget and the delivery remained stable.
Initially I thought it might have been a fluke but I subsequently applied the approach to other migration and integration programmes in regulated and retail environments and the results were consistently similar.
Lessons I learned
Although the process worked well there were a few things I learned along the way.
1. Avoid the “rabbit hole”.
The whole point of the process is to complement Agile and not become Waterfall. By limiting the depth of steps you work backwards, you prevent analysis paralysis.
2 . Business stakeholders need alignment.
Stakeholders can be impatient. Once they’ve signed off on a project, they want to see progress, so you need to explain to stakeholders the value of allowing time to perform the BackBuild process before forming the teams. The pitch is that it’s an insurance policy and an accelerator. To go faster, you need clarity first otherwise you’ll just reach chaos faster.
3. The “Loop” is critical.
BackBuild only works if discoveries update the original map. If you don’t do this then the Waterfall risk becomes real because the plan stops reflecting reality.
4. Keep it alive without you.
The original BackBuild team members must keep the process going. If they don’t then the old failure mode can return. I learnt this the hard way when I took a couple of weeks leave. You don’t want a single point of failure.
If you want the full process
After seeing this pattern repeatedly, I formalised the approach into a ten-step process for complex delivery. The full BackBuild guide, with workshop formats and visuals, is available free at https://arcaned.co/backbuild
Start from the end. Work backwards. Build with foresight.