
Hackathons are one of the fastest ways to move from idea to working prototype.
In just a few days, teams can test a concept end-to-end, uncover unexpected blockers, and walk away with something that actually runs.
At Corefy, we wanted to see how far this format could be pushed if we combined two strong accelerators: n8n for low-code automation and AI models for data enrichment and parsing. The bet was simple — if hackathons are rapid prototyping engines, then automation and AI should make them even more productive.
The idea for the hackathon itself came from our CEO. I joined as a participant, and as a product manager, I was particularly interested in what this kind of compressed, build-first environment could reveal that traditional discovery often doesn’t.
We ran a 3-day internal hackathon: four teams, one shared stack (n8n, our internal tooling, PostgreSQL), and a set of deliberately “boring but crucial” operational challenges every SaaS platform faces: cleaning messy data, enriching incomplete records, and tracking upstream outages.
By Sunday evening, we had working modules — scrapers, aggregators, enrichment pipelines — some of which are already being refined further. More importantly for me, the process surfaced very concrete signals about which problems were worth deeper investment, and which ideas looked good on paper but broke down quickly in practice.
In this article, I’ll walk through what we built with n8n and AI, and what participating in this hackathon taught me about product discovery along the way.
Why we focused on boring operational problems
In payments, complexity is the default. Corefy is a payment orchestration platform that connects businesses to hundreds of payment providers worldwide. Alongside it, we’ve been developing PayAtlas — a knowledge hub for the payments industry where data about providers, their capabilities, and reliability comes together in one place.
That diversity is powerful, but it also means teams spend a lot of time on work that isn’t glamorous but is absolutely critical:
- Cleaning up dirty data: broken links, outdated logos, incomplete provider profiles
- Filling in missing information when all you have is a name and a URL
- Tracking outages and figuring out whether a failure is local or upstream
These are the invisible chores that keep platforms like PayAtlas useful and trustworthy. But doing them manually doesn’t scale. It slows down integration, increases support load, and leaves users in the dark when something breaks.
From a product perspective, these problems are tricky: they rarely scream for attention individually, but together they have a disproportionate impact on trust and operational confidence.
That’s why automation of these boring-but-crucial tasks became the central theme of the hackathon. Instead of chasing ambitious new features, teams focused on turning these pains into automated workflows: aggregating provider status feeds, enriching profiles with metadata, and detecting issues early.
The guiding question was simple: can n8n and AI help us ship viable solutions to these problems fast enough to understand whether they’re worth deeper product investment?
Why n8n and AI worked under hackathon constraints
Going into the hackathon, the goal was to see whether we could get from a fuzzy operational problem to a working, end-to-end solution within days — fast enough to expose real constraints instead of debating them.
That’s why most teams gravitated toward n8n and AI models almost immediately.
n8n gave us a way to build workflows visually, connect APIs, scrape data, and transform it without spending half the hackathon setting up boilerplate. For problems like status aggregation or metadata enrichment, that speed mattered more than perfect abstractions.
AI filled in another gap. Many of the tasks we were tackling — finding official provider websites, extracting logos and descriptions, normalising messy inputs — are painful to solve deterministically. Using AI models as a first pass lets teams move forward quickly, even if the output wasn’t perfect.
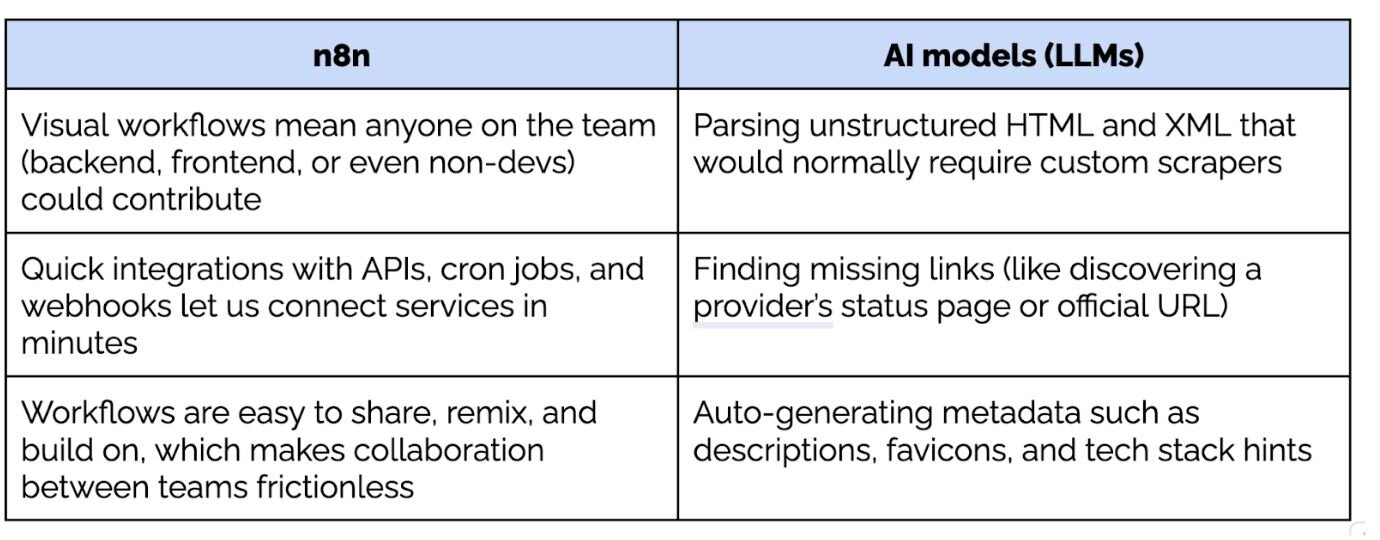
What mattered wasn’t accuracy at 100%. It was whether the approach held up at all once real data entered the system.
In several cases, a few hours of building with n8n and AI surfaced issues that would have taken weeks to uncover through planning alone: unreliable sources, edge cases in scraping, or assumptions about data quality that simply didn’t hold.
For me, this reinforced an important product lesson. When you’re exploring operational problems, tools that let you move fast and stay close to reality are often more valuable than technically “correct” solutions that take longer to stand up.
In early discovery, the most valuable tools are often the ones that optimise for learning speed rather than architectural purity. n8n and AI models lowered the cost of being wrong quickly, which meant weak assumptions surfaced almost immediately. As a product manager, that shift matters: it changes discovery from a debate about feasibility into a confrontation with reality, where ideas either survive contact with real data or they don’t.
What we built in 3 days (and how)
With just a weekend to work, each team picked a single operational problem and tried to push it from idea to something runnable. The goal was to see how these problems behaved once they were forced into an end-to-end flow.
What mattered most was where teams slowed down, what broke under real data, and which ideas stayed coherent even when time ran out.
1. Status feed aggregator
The problem: outages at providers are hard to track in real time. Status pages exist, but they’re scattered across dozens of websites and formats. When something goes wrong, it’s often unclear whether an issue is local or caused by an upstream provider.
The solution: a cron-driven workflow in n8n that fetches RSS and Atom feeds from provider status pages, parses them, and stores incidents in Directus as a clean event history.
Outcome: a live log of provider uptime and incident tracking, with potential to power heatmaps, alerts, and even public dashboards.
What this revealed:
Even “standard” status feeds varied wildly in structure and terminology, which quickly exposed how much hidden work sits behind something that looks simple on a roadmap.
2. Metadata enrichment engines
The problem: too many provider profiles started as just a name and a URL. Manually enriching them with descriptions, logos, and metadata was slow, error-prone, and didn’t scale.
The solutions (two approaches):
- AI-assisted search: an LLM finds the official provider website, after which n8n scrapes meta tags, favicons, and logos to auto-fill the profile.
- Deterministic scraping: a more rule-based approach that parses known fields directly from HTML using predefined selectors.
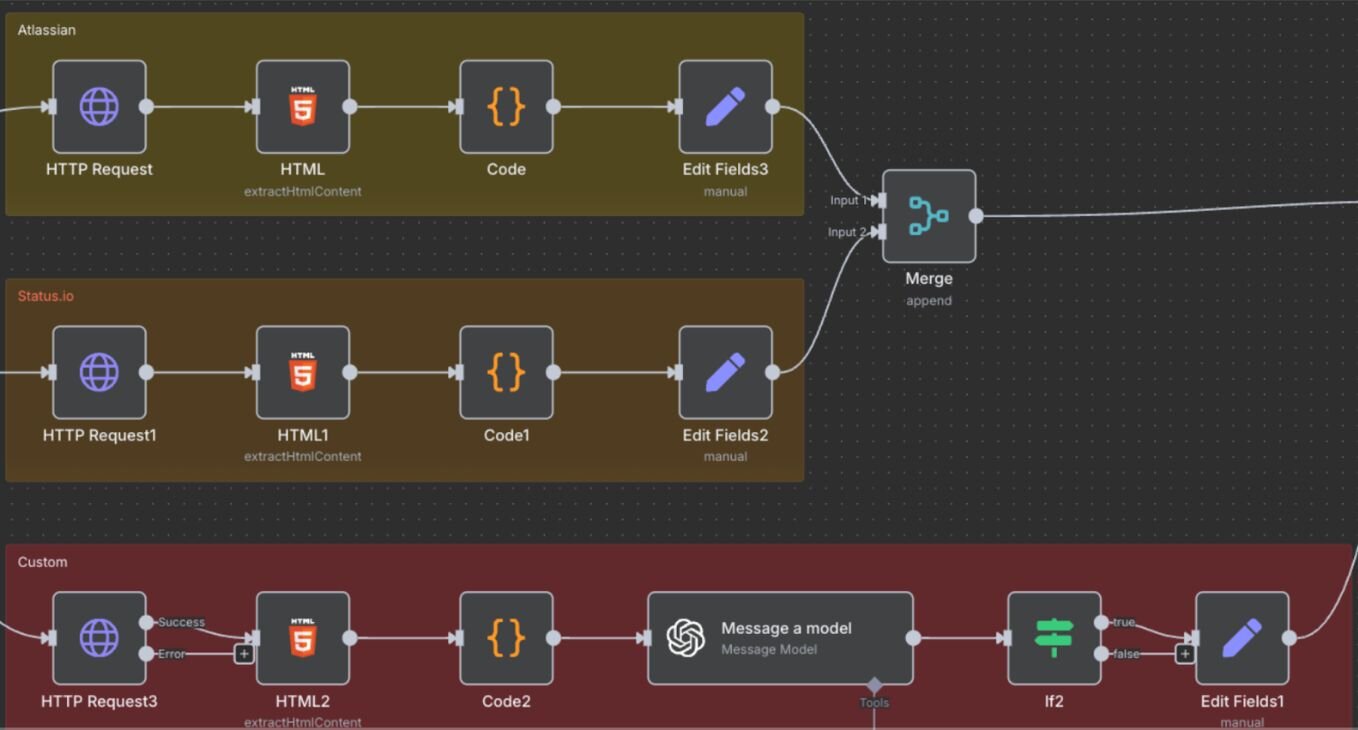
Both workflows were built end-to-end during the hackathon and connected back to Directus.
What this revealed: the AI-assisted approach handled ambiguity better and got teams moving faster, while the deterministic one surfaced edge cases and consistency issues earlier. Seeing both side by side made it clear that enrichment wasn’t a single problem to solve, but a spectrum of trade-offs between speed, accuracy, and maintenance.
3. Additional experiments
Several teams extended the core pipelines with small but practical enhancements. For me, these “extras” were some of the most useful discovery signals. They showed what people naturally reached for once the core flow was working, and what they considered missing for the solution to be usable.
- Change-based notifications: emitting events when derived status transitions occur (so something downstream can alert or react).
- Tech stack inference: lightweight heuristics based on DOM patterns and public documentation — useful, but also a quick reminder that anything inferred needs validation.
- Minimal dashboards: simple grids driven by aggregated JSON endpoints rather than tightly coupled UIs, which kept UI effort low while still making status changes visible.
Each experiment reused the same core primitives: scheduled ingestion, normalization, append-only storage, and derived views. That consistency mattered: it made it easy to compare approaches and decide what was genuinely reusable beyond the hackathon.
What stood out after three days
By the end of the hackathon, a few things stood out to me as a product manager:
- Boring problems resist abstraction. Tasks like data enrichment or status tracking look simple on a roadmap, but once you try to automate them, edge cases appear immediately. That friction is useful — it shows where real product work would begin.
- Speed exposed false assumptions early. Using n8n and AI made it possible to test ideas fast enough that weak assumptions didn’t survive the weekend. Some approaches collapsed within hours; others stayed coherent even when time ran out.
- End-to-end flows mattered more than features. The most promising experiments weren’t the most sophisticated ones, but the ones that closed the loop: ingesting data, normalising it, and making it visible or actionable somewhere downstream.
- Reuse emerged naturally, not by design. Teams that leaned on the same primitives — scheduled ingestion, append-only storage, derived views — were able to extend their solutions with minimal effort. That was a strong signal of what might be worth investing in further.
Looking back, the biggest takeaway for me is that hackathons can be a powerful form of product discovery, but only for a specific class of problems. They work best when the unknowns are operational, technical, or data-driven, and when seeing something run is the fastest way to expose risk. Used deliberately by turning abstract ideas into concrete constraints early enough to matter.