Jonathan Evens, AI Product Lead at Google Deepmind, opened his talk at #mtpcon London 2026 by explaining that as a product manager, he physically feels an itch when something's wrong with a product. Netflix, he told the room, gives him that itch constantly.
The recommendations aren't good enough. Some shows clearly don't need eight seasons, and movies he was planning to watch randomly disappear. He asked the audience: Which of those pain points would you actually solve with an AI feature? That instinct to fix it with AI, he argues, is an opportunity to reinvent the feed with natural language, giving users more specific control over what they see.
He then pushes further: if you were building Netflix from scratch in 2026, what would you build? He suggests it would be something like "AIFlix", AI co-produced content networks. Infinite branching storylines. A many-to-many social platform that democratises access to producer skills. Each idea represents a different kind of AI product challenge: bolting a feature onto something that exists, versus building something new from the ground up.
Jonathan's talk (speaking in a personal capacity, not on behalf of Google) focuses on this very contrast. He is an AI product leader who has worked across nuclear fusion platforms, recommender systems, and LLM search tools. At Google DeepMind, he's focused on integrating Gemini into Google Search, while at his nonprofit, the Evens Foundation, he's building civic tech with a team of under ten and a fraction of the budget. He uses both as case studies in how to find and ship the right AI opportunity, whatever your constraints.
Watch the video in full, or read on for his key points.
Launching AI in a product operating at scale
Jonathan takes the audience through the evolution of Google Search over its lifespan, from 10 blue links in 2000 to a myriad search engine features in the 2010s. Over the last three years, the product team has executed a full transformation, with AI Overviews being at the top of the page, followed by AI Mode.
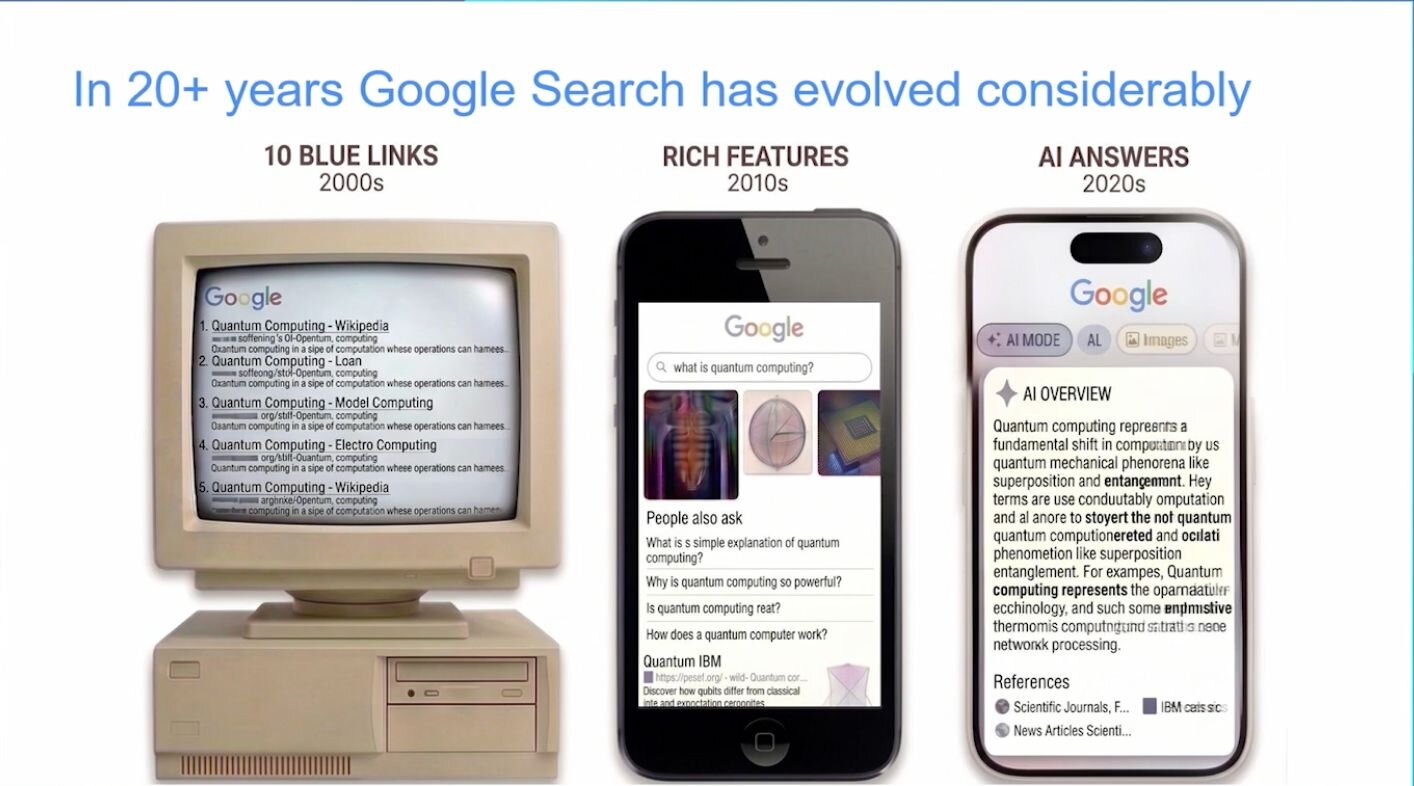
But where would a new AI feature fit into the current product? The Google DeepMind product team looked for pain points AI could specifically solve. One they landed on was that every time you search Google, there's a vast space of information you have to cross-reference with your own context, such as preferences, situation, history, all of which you build from scratch each visit. That pain point led to personalisation.
The goal of the feature, Jonathan explains, was straightforward: users should feel, from day one, that the product gets them. Not "interesting, it's noticed I used to watch a lot of cooking videos three years ago." Actually gets them, based on current activity and real context.
Competing with your own product
Designing an AI feature for an existing product means that you're competing with a high-quality experience that's already there. Jonathan and his team had to translate this feature's success into the language of the overall product, while keeping in mind that its value to users would be both subjective and objective, therefore very difficult to measure accurately.
Because the AI feature wasn't going to outperform on everything from day one, the team had to be deliberate about their focus. They looked for use cases where their differentiators would shine, such as complex queries, overwhelming numbers of options, and situations where history and intent mattered.
Combined with a Gmail integration, they landed on two hero use cases: local dining and shopping.
Power users, LLMs, and why privacy complicates everything
Jonathan broke down the several technical and privacy challenges the team encountered. The first being that LLMs are non-deterministic by nature—you have to build in an expectation that you're learning as you go. That's why power users, highly engaged customers who use advanced features and workflows that casual users typically ignore, are essential, as they're the first version of a human in the loop. “You have to build a strong experience for all users over time, but start with the power users to gain a consensus,” he explained.
To enable the power users more, the product team launched Search Labs, an opt-in environment, which constrained the experience to a few million users. This created better conditions for experimentation and feedback.
Evals aren’t all you need
On evaluations, Jonathan pushes back on the "evals are all you need" framing that's become common in the product industry. He agrees the principle is right, but "it's not one-size-fits-all."
For example, Google search holds vast amounts of historical user activity, but human raters are disqualified from reviewing it. They can't look at someone's private data, and even if they could, the volume makes it impossible to get the full picture. The eval method had to be rebuilt from scratch to fit the constraints of the feature.
The team's solution was auto-raters: AI evaluators that could process private data at scale, safely and efficiently. The remaining problem, measuring subjectivity in personalised suggestions, was still an active AI research question, one that ultimately required Google DeepMind's in-house expertise to crack.
But measuring subjectivity remained unsolved, more specifically what personalised auto-raters need to do. That was an in-progress AI research problem, and solving it required in-house expertise from Google DeepMind. "That was the difference between a demo and a real feature," Jonathan adds.
His takeaways from launching at scale:
- Start with pain points and match them to genuine AI advantages.
- Prove the new feature adds more value than the existing experience.
- Identify the technical dependencies early, especially if your feature depends on AI research that hasn't been solved yet.
Building at scale vs building from scratch
Jonathan's second case study is building an AI-native product at the Evens Foundation, with a much smaller team and budget. The Evens Foundation is a small nonprofit operating at the intersection of youth, democracy, and technology, whose goal is to build early-stage civic tech. They run a small team of under ten people.
When looking for opportunities to build an AI-native product, Evens uses three criteria:
- Are there time-consuming tasks that could be automated, or aspirational tasks that simply haven't been attempted because the resources weren't there?
- Can we lower barriers to knowledge or insights?
- Can we create a safe, in-silico environment where users can try approaches they'd never dare to try in the real world?
Those questions led the team to political decision-making. Today, politicians rely on polls, focus groups, and social media to understand public sentiment. Polls take weeks and tend to be surface-level, while citizens' assemblies produce deep insight but can take years. Additionally, governments rarely know what people think privately. And there's no safe space for political leaders to experiment with policy ideas before taking them public.
The opportunity seemed clear, Jonathan explains, for an AI-native product that would offer digital citizenry, a democracy sandbox where synthetic citizens deliberate by simulating human behaviours, opinions, and interactions. The goal was to create a better representation of human values in the final policy.
They narrowed the use case space from around fifty options down to three:
- Local governments running citizens' assemblies
- Party leaders testing reactions to campaign material
- Public officials polling constituents
The core technical problem Jonathan and his team ran into was that when LLMs are prompted to mimic a persona, they're less diverse and more extreme than real humans.
The solution was conditioning prompts with a persona model, which turned out to be an AI research problem the foundation couldn't solve in-house. So, they partnered with the Cooperative AI Foundation, the FAIR Institute, and Culture Dynamics, who specialise in exactly this kind of model. Meanwhile the Evens Foundation focused on product development and funding.
Imperfect evaluations are still evaluations
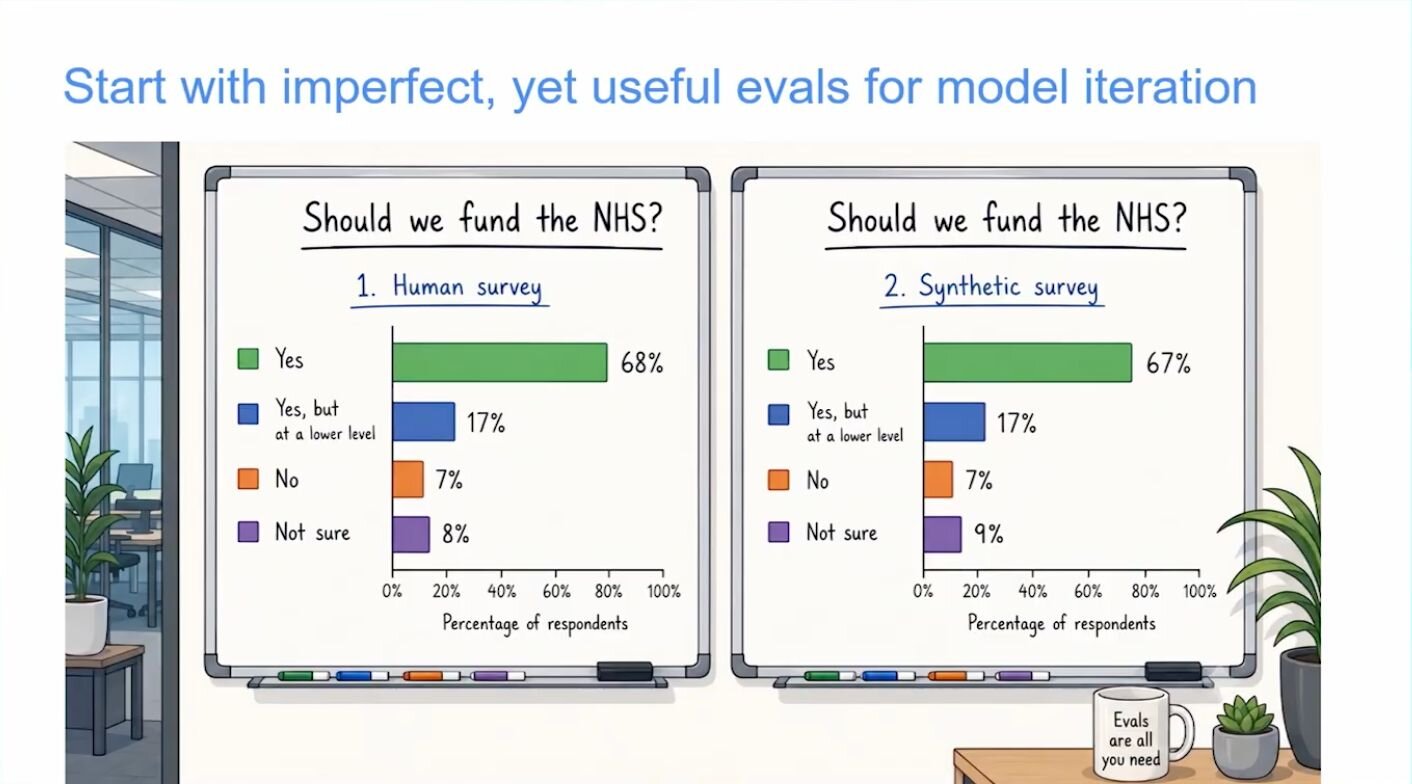
With around 2,000 real surveys mapped to over 100 human values, the team measured the distance between synthetic respondents and humans. The result was roughly 10% difference, which was comparable, Jonathan notes, to the 10–20% variance in how humans answer the same questions about themselves within just a few weeks.
“Not perfect. But useful. You don't need to get it right from day one," he adds. Imperfect but useful evaluations are enough to start the flywheel, bring the product to users, gather feedback, and improve.
With no full-time developer on the team, vibe coding tools got them to a good-enough UI for an MVP.
They built three core workflows:
- One that lets a user ask any question to a simulated public universe
- One that tests public reaction to political material like a party manifesto
- One that compares the digital citizenry's outputs against known studies, so users can calibrate how much to trust it
The shape of both problems
The two examples Jonathan shared sit at opposite ends of a scale: massive vs small product, team, and budget.
For building AI features at scale, the most important thing is evolving an existing product, transforming it while solving real user pain points. The main risk here, he adds, is breaking user trust.
On the other hand, with a brand new AI product, it’s important to think about how you can disrupt the space you're targeting. The main question here is whether to pursue it at all.
In both of the case studies from Jonathan's talk, evaluations were essential, but had to be redesigned to fit the specific problem. And in both cases, the path forward was: finding a pain point AI can actually solve, matching it to what AI does well, and building the trust of a small group of users before scaling.
The main takeaway from Jonathan's presentation is simple: whether you're launching a feature for a billion-person product or building a civic tech MVP with ten people, the foundational best practices you focus on are more similar than they might appear.