
Our startup adventure begins with a team composed of a product manager, a tech lead, a full-stack developer, a UI designer, a QA tester, and a user researcher. We’ve always shared the desire to create new products we would be proud of, so one day we decided to leave the previous company we were all working at to build our startup. In this article, we will share some learnings about a widely-perceived problem for product teams: incomplete bug reports. We will also discuss how to improve your reporting workflow to speed up the resolution of bugs.
Doing the right thing and doing it the right way
Before we get to the crux of improving your process, let’s take a closer look at the journey we took that ultimately allowed us to understand that improving bug reporting workflows deserves more attention.
Doing things the right way increases efficiency. Yet, oftentimes the most natural thing to do is hardly the right one. This is what happened to us in the very first months of our startup. Like many of you surely know, what you should be doing before developing a product, and even more during the very first months of a product-based startup, is NOT building and developing solutions.
“Fall in love with the problem” – the most popular recommendation shared among product people, and those founding a new startup. But here we’re talking about a startup whose 80% is made of builders, people who love to do one specific thing: build solutions. As Dan Olsen once said, “We all live in the solution space”, and this is definitely true when talking about tech teams. That’s why we initially took an unwise shortcut: validating a solution without having validated the problem. We began this adventure with a solution in mind, a leftover from our previous experience, and went looking for a fitting problem, and for a market segment that could be interested. A bit like when you’re a child playing with geometric wooden shapes and you try to fit a circle where you should put a square. A nightmare.

Luckily for us, after banging our heads against a few brick walls, we realized that the solution we were developing wasn’t going far: there was no problem-solution fit. We hit the brakes and pivoted away.
We braced ourselves with patience and started our quest for a problem that was worth solving: “since we are a product team”, we said, “let’s start exploring some product-team-specific processes”. We deep-dived into processes related to developing new features, and those related to the resolution of bugs and technical incidents. Of course, fixing bugs appealed to us much more than developing new sexy features!
We’ve spent the last five months doing customer discovery, interviewing potential customers, texting them on LinkedIn and Reddit, on Discord channels, and in many product communities active on Slack (p.s. If you ever need feedback on any product you’re working on, I’d suggest asking folks in Mind The Product. Everybody is super generous with their feedback and ready to help out). As you can imagine, we had to work against the natural tendency to find shelter in the solution space, especially when at first we couldn’t get many people to talk to. But we managed, mostly because we were scared otherwise we would have to pivot again, and that’s a very painful process, as some of you can surely confirm. So after having chatted with hundreds of people among product managers, customer support reps, and account managers working for very diverse companies, we validated that indeed there is a real problem with bug reporting.
Read more case studies on Mind the Product.
What does the current bug reporting process look like in many organizations?
Apart from some specific peculiarities that define every company, the process that is followed in many places can be simplified like this: bugs (or presumed ones) found by end-users are reported to customer support (CS), who are then responsible for the thankless task of manually collecting some technical information that is often hard to get: just imagine you need to ask an average user to share the screen and use the browser inspector to be able to check console logs. Then the CS agent opens an issue to report that information in a ticketing system, following a more or less structured process.
This process creates a clear bottleneck: the team responsible for the bug resolution receives a report that is often incomplete. Not only doesn’t that help identify the steps to reproduce the error, but incomplete reports often lack the technical specs needed to distinguish between a real bug and a device/user-specific error, or even a bad design. This is why, once the ticket is opened, bug reporters and developers initiate a conversation that goes back and forth several times to grasp the missing details. Sometimes, CS agents are even forced to reach out again to the end-user to find out more about the bug. This bottleneck is strongly felt by both parties involved: it is an eternal ping-pong that leads to a waste of time, without having any assurance that the bug will eventually be identified and fixed.
Here we’d love to share with you some of the most interesting learnings we gathered on the way:
1. There is no need for a process…until you need one!
The very first thing we learned during our customer interviews is that there is a specific moment when you realize that your team won’t survive if you don’t put in place a somehow structured bug reporting process. We noticed that teams usually move from receiving direct calls or Slack messages from colleagues finding bugs to having a dedicated space to collect all reports. You can have a basic version of this, like a shared spreadsheet, or an #issues Slack channel where the tech team manages to gather all complaints shared by colleagues. Those in need and the bravest, too, even go a step further and build a template to guide colleagues in what details they need to reproduce and triage the bug, so they can quickly define its priority in the backlog.
What are the details that, if present, speed up the whole bug reporting process?
- Where is the bug? – That is, all information that allows the team to exclude problems that are not widespread, but related to certain devices, OSs, browsers, app versions, or even user IDs.
- Steps to reproduce – The actions that led the user to find the issue. The golden rule is “the more detailed, the better”. Usually, this information can be obtained only by directly asking the end-user to describe the process they follow that brought them to the bug.
- Expected behavior – Bugs are very often unfortunate design choices that produce some friction when using the product. To be able to spot these non-bugs, it’s important to ask the user to clarify what behavior they were otherwise expecting to see.
- Technical details – In an ideal world, frontloading helps make the bug resolution process overall more efficient. This is why it is a good practice to immediately collect all those technical details which could later help testers and developers identify the issue, such as network requests, and console logs. When reproducing the bug is not straightforward, details like these come really in handy. Yet, collecting them is a real pain for non-technical colleagues who have to directly ask customers and users. Imagine asking a user to share their screen and activate the Browser inspector so that you can collect the logs. A bit of an extreme situation, especially when dealing with users with low digital literacy.
- Priority – The goal is to provide the tech team with an estimation of how quickly they should act on the bug and plan accordingly for the next sprint. This metric can be determined by different factors, such as the number of users that could experience the bug, or the importance of the feature that results affected, but also the impact of the reporting client on the company’s total revenue.
Unfortunately, the truth is that all the effort put into providing colleagues with a template that guides them to report a bug doesn’t always pay off. There will always be someone who won’t follow the suggestions, who prefers to spontaneously make a phone call or send a Slack message directly to the product manager or a developer. And from here we move to the second learning.
2. Templates are useful, but never enough
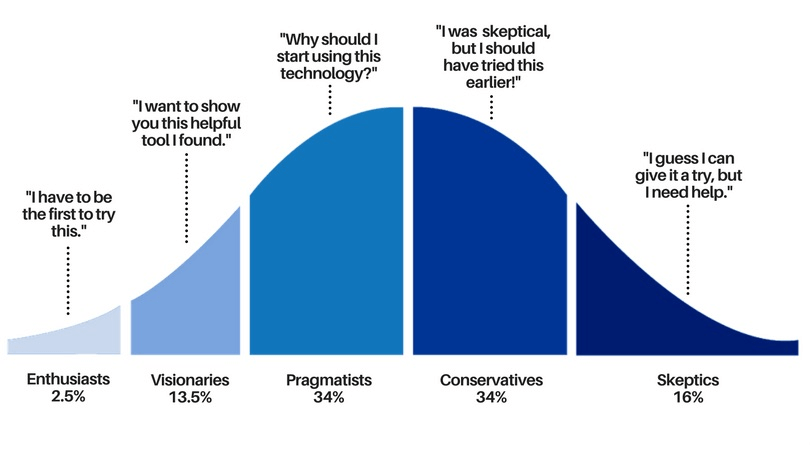
At least once in our professional life, we’ve all witnessed a colleague who refused to use a new tool that would have facilitated and sped up not only their work but everybody else’s. This is because the adoption curve for an internal tool of this kind follows the sinusoidal shape of any other technological innovation introduced in the last two centuries (but have a look here to read how the pace is gradually speeding up).
What’s important to bear in mind is that for any new tool or process, there will be one or two colleagues out of ten who will enthusiastically try it out – the so-called innovators and early adopters. Of the remaining eight, though, seven will need to be convinced, pushed, and engaged even just to give it a try, and one-two will likely never accept change. This is the truth, it hurts, but the sooner we accept it, the better.
3. Priority is not mathematics
Chatting with many product managers we identified another very painful point: even when you have some guidelines about how to estimate a bug priority, non-tech colleagues always report “High priority”.
“Consider, high priority is given even when they are talking about a typo or a misaligned button in the interface of an internal-use-only platform”, many confess with frustration.
This is truly one of those cases where you get nowhere: every team has its own KPIs and success metrics. If we ask a CS rep, they will say their goal is closing support tickets as fast as possible. If we interrogate an account manager, it is high retention rates and an NPS equal to or higher than 9. And indeed, helping the unsatisfied user or client by making sure the problem is fastly and efficiently handled seems a very high priority for these roles, which are usually the most active in reporting bugs and technical issues in the first place.

The only thing we can do is consider this factor, and use some empathy – yep, the same empathy we try to use with our users! These colleagues have different goals and jobs to be done, so get ready with a bug triage process that is independent of the reported level of priority. From here we move to the next learning: the (oftentimes unsatisfying) conversations between the tech team and non-tech colleagues.
4. “Yep, sure! I’ll let you know” doesn’t work
We’ve just mentioned that the product/tech team’s KPIs are quite different compared to those of colleagues working in sales and CS. Let’s play a role game and get in our colleagues’ shoes -we have to apply that empathy we mentioned above: I’m a CS agent and a client contacts me to report a technical issue, I bring this information to the tech team after collecting as many details as I can (although I’m sure the developer won’t be satisfied, as usual). It should go without saying that my need is to be able to check the status of my report so that I can show the client that I’ve not forgotten about them, I’ve paid attention and made sure their problems will be solved asap. Even when they contact me again the following days. It’s easy now to empathize with this colleague, isn’t it?
Then you should be surprised to hear that many of the customer care reps or account managers we talked to are not satisfied. The “Yep, sure! I’ll let you know” they receive from their tech colleagues doesn’t satisfy their simple needs. Most importantly, it doesn’t give them the chance to do their job at their best. Of course, we cannot expect the same colleague to then go the extra mile to gather all the details to make our job easier and less frustrating, am I not right?
Companies that believe in a powerful alignment between product and sales/customer care invest a bit and provide non-tech colleagues access to the product’s task management platform (e.g., Jira, Trello, or ClickUp just to name the most mentioned). In this way, as a task progresses, the colleague receives a notification and can address the angry client who’ll get in touch again the following day.
5. QA testing is not sufficient
The very last learning we want to share is about testing, and here we collected mixed feelings. On paper, all product teams acknowledge how important it is to have a testing procedure in the pipeline before releasing changes to production. This procedure should guarantee that code is error-free, what’s known as Quality Assurance (QA) testing, but also that the user experience and the app usability are optimized, known as User Acceptance Testing (UAT). Everybody agrees this should happen.
Yet, about half of the people we interviewed confessed they don’t have dedicated resources for testing activities. In some cases it’s the product manager who carries out the task, testing the product and trying to imitate dummy user’s behaviors, such as clicking on the wrong buttons. In other cases, it’s the developers who test what they just built – and here we could (but won’t) start the huge debate on the validity of this practice (refer to this article to check popular arguments on the topic).
Nevertheless, there are several organizations where not only is QA testing done properly, but it is also automated to be very efficient and limit human errors. Nowadays many tools automatically notify you when they find code-specific errors, nothing new on this site. Yet, as many confirmed, the problem is that many bugs are not real bugs (strictly speaking, only code-specific errors are). Most of the time, the “bugs” are unfortunate UI/UX choices that the user perceives as technical issues. These cases represent the majority of the reports that tech teams receive, according to the product managers we interviewed, and there isn’t much we can do except bracing ourselves with patience and a desire to improve.
To sum up, we mentioned the necessity to set in place a process so that your non-tech colleagues understand the information to gather when reporting a bug, and we saw that a template can prove very handy in those circumstances. Yet, we also noted that the adoption of such new practices may likely face some colleagues’ resistance to change, as in any innovation instantiation. Likewise, our colleagues’ priorities will often differ from those of the product and tech teams so we should triage bugs independently of the reported priority. Finally, we mentioned that while UAT and QA testing should always be part of any development pipeline, many times they may not allow us to catch some frustration users experience due to bad design choices, that are not strictly speaking dependent on code errors. The best way to cope with it is to have some buffers for these events to allow your team to handle these cases most efficiently. We hope the learnings we shared can help you improve your bug reporting workflow and make it less painful and time-consuming.
Read Third-party integration — Product Manager’s guide on how to choose a vendor
Adopto Bug Fix: a step further in speeding up the process
If you are wondering how our startup’s story progresses after having learned to carry out a proper customer and problem discovery: thanks to the interviews, we identified the pain points related to the job-to-be-done and moved to the solution space. And here we started defining and building Adopto Bug Fix: an automated bug reporting tool that helps tech teams receive fast and detailed bug reports, without wasting time and precious resources in back-and-forth conversations with customer care and end-users.
Picture this: a user contacts a CS to report a technical issue, the rep simply asks the user to press a keyboard shortcut, or click on a button on the app, and reproduce the steps that led to the error in the first place (this last one is a standard procedure that CS usually follow when receiving a report). That’s all!
Adopto Bug Fix works with a snippet of code that is pasted into the target platform’s code. It behaves like Siri: it’s quiet and invisible to the users’ eyes unless it’s activated. After the activation (with a keyboard shortcut or a button click), Adopto starts recording the session and collects a series of information. Among the information, there is a screen recording to check the user’s behavior on the app, the user clicks and text input, console logs, and network requests. But also specs about device and OS, screen resolution, and user ID. All these structured details are then conveyed in a report that the team can access from our platform. The report can be easily shared in any task management system. In this way, you can exploit the existing process you may already follow to share updates with non-tech colleagues (we mentioned this at point 4).
As for today, we are in the Beta phase, iteratively improving the user experience and developing new functionalities thanks to the help of some product teams who are currently using Adopto in their bug reporting workflows.
These teams are young (not talking about age, but product maturity), have a WepApp currently under development, receive many incomplete bug reports from end-users and colleagues, and have tried to solve the problem with a solution that didn’t bring the expected results. If you see yourselves in this description and believe Adopto could make your team’s life easier, check out our webpage and sign up to for our Beta program! Sign up for free for our Beta program
There's more where that came come!
- Prioritization: How to get rid of Those Pesky Bugs?
- A case study: Building a product without any full-time product managers