
Artificial intelligence (AI) is probably the biggest commercial opportunity in today’s economy. What does it mean for us as product managers?

We all use AI or machine learning (ML)-driven products almost every day, and the number of these products will be growing exponentially over the next couple of years. According to Crunchbase, in 2018 there were 5,000 startups relying on machine learning for their main and ancillary applications, products, and services. Just one year later, there have been almost 9,000 of them.
Artificial intelligence is considered the fourth industrial revolution. By 2030, it is expected to contribute $15.7 trillion to global GDP, “making it the biggest commercial opportunity in today’s fast changing economy”, according to a recent report by PwC. And, like all industrial revolutions, it will have a great impact not only on our economy, but all other aspects of our lives.
What does it mean for us as product managers? Firstly, as business owners realise the impact of AI and integrate it into key business processes, it will be increasingly important to understand at least some AI basics, even for those who don’t work with AI products. Secondly, as great product managers are also great capacity builders for their teams, you should start looking for opportunities that AI can present for your product.
I’d like to share five lessons from my experience that can help you start your own journey.
Lesson 1: Understand the Problem You’re Trying to Solve with ML

Each product development process starts with identifying the right problem to solve: you all remember that users don’t buy a drill for a drill itself or for a beautiful hole that this drill can make, they buy it for a nice dining room they want to decorate with a picture. But with machine learning the solution itself is so exciting and novel that it’s tempting to forget to ask yourself why you need it in the first place. When a new iPhone comes out, for some people it’s more about joining the hype and standing in the queue than about new functionality.
From my experience, the problems that ML can help to solve usually fall into one of these buckets below:
Could we make the user experience more tailored and personalised?
Imagine that you're going to a coffee shop. Which would you prefer: one where a barista knows your name and your favourite drink and your favourite music is playing, or one where everything is made for an average customer? For a long time we were building products for the majority – that's how mass production works – but in a world where personalisation becomes possible at scale, we can and should build for everyone.
People have a limited budget, not only when it comes to money, but attention as well. At Workplace, where I work, News Feed helps people connect to the most relevant work updates so that when they have only one minute to spend, they would read the most important piece of content they should know about.
To identify these issues, you would usually need to combine observation and data analysis. In the case of the News Feed, this would mean asking if people have a lot of new posts that they don’t go through. If so, ranking could help. Or do they have very few posts in their inventory but there is much more discovery content available? If so, it’s probably a recommendation problem.
Could we make the user experience safer?
Spam engines are the most famous example here but there is much more. Anomaly detection is used to identify suspicious bank transactions or fake accounts. Integrity classifiers allow to flag harmful or malicious user-generated content. Previously, most of these things required a lot of human effort, and now given the enormous growth of the digital world would be impossible without ML.
To identify these issues, you would need to do a very thorough risk analysis and understand the potential implications for your product.
Could we help users to achieve their goals easier or faster?
Can I reduce a number of steps to complete a task? For example, if I need to write an email, there is an autocomplete feature that enables me to do it faster. If I need to buy food for a week, there is a section “With this product customers usually buy…”.
To identify these issues, we should know what the user journey looks like: what are users trying to achieve with our product and what steps do they have to take?
Could we create a new experience that previously was not possible?
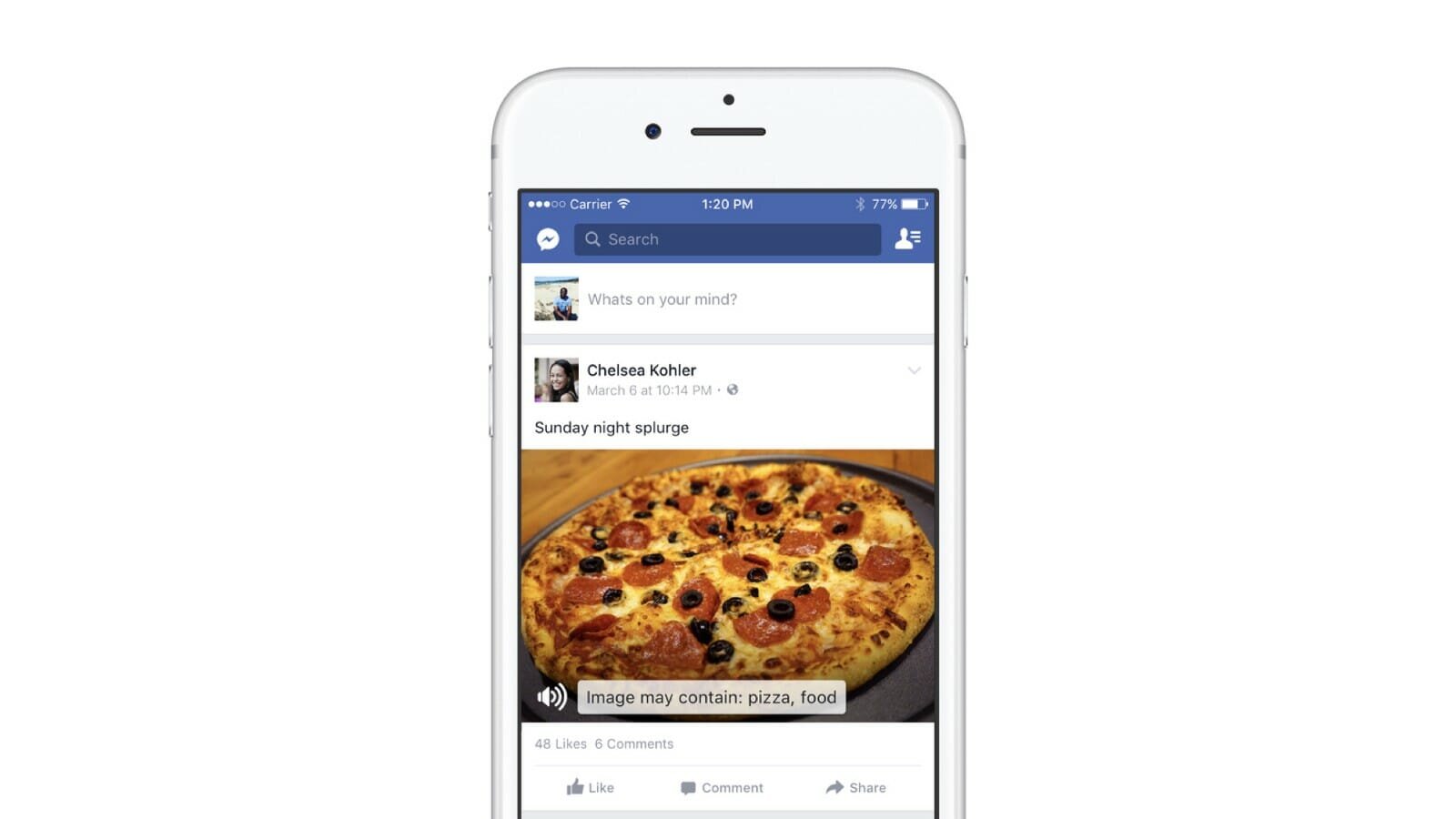
For example, with over 36 million blind people , and over 217 million with a mild to severe visual impairment (WHO, 2018), many people may feel excluded from online conversations around photos. The automatic alternative text feature in Facebook the generation of descriptions of photos that can be played by those users through a screen reader so they can join a discussion.
The only way to identify these issues is to have a deep understanding of user needs and pain points.
Overall, the key challenge here is that users rarely talk about these kinds of issues and rarely request features that could help us infer the existence of such issues. That’s why it’s incredibly important to develop a good level of empathy and user understanding, not only for yourself, but for the whole team. Problem understanding will affect what data we decide to collect, features to build, model to choose, and, finally, how to define success: so it’s essential to ensure that all team members are on the same page.
Lesson 2: Assess if ML is the Best way to Solve the Problem
When I was at a startup working on hotel-guest communication through in-room tablets, one of the engineers had the idea to build a chatbot that would help guests quickly find relevant information about their stay. It would also reduce the workload for receptionists who usually have to answer such questions. We talked to receptionists and quickly identified that 85% of questions from hotel guests came from the list below:
- When is the check-out time?
- When is breakfast?
- And what is the wi-fi password?
We built a widget that would answer all these questions as soon as a guest took a tablet into their hands. Next we tried to understand if there was any value in answering the remaining 15% of queries with ML. We did a classic “Wizard of Oz” experiment where we installed a chat widget on our tablets but all the questions were handled by real people, not by bots. We learned that most of these remaining queries required human assistance to be resolved (for example, can I have an iron?) so there was no value either in using chat or in any complex models to answer these questions.
ML takes time and effort to build into your product. You need good people, good data and a good number of iterations to achieve sufficient quality – sometimes it might take over a year of work or even more. Is it something you're happy to invest in, or would a simple, more basic heuristic be enough?
Here's another example: If we're developing an email client and would like to catch cases when users may have forgotten to add an attachment, we could simply do a keyword search for “attachment” and “attached”. An ML system would probably catch more mistakes but would be far more expensive to build.
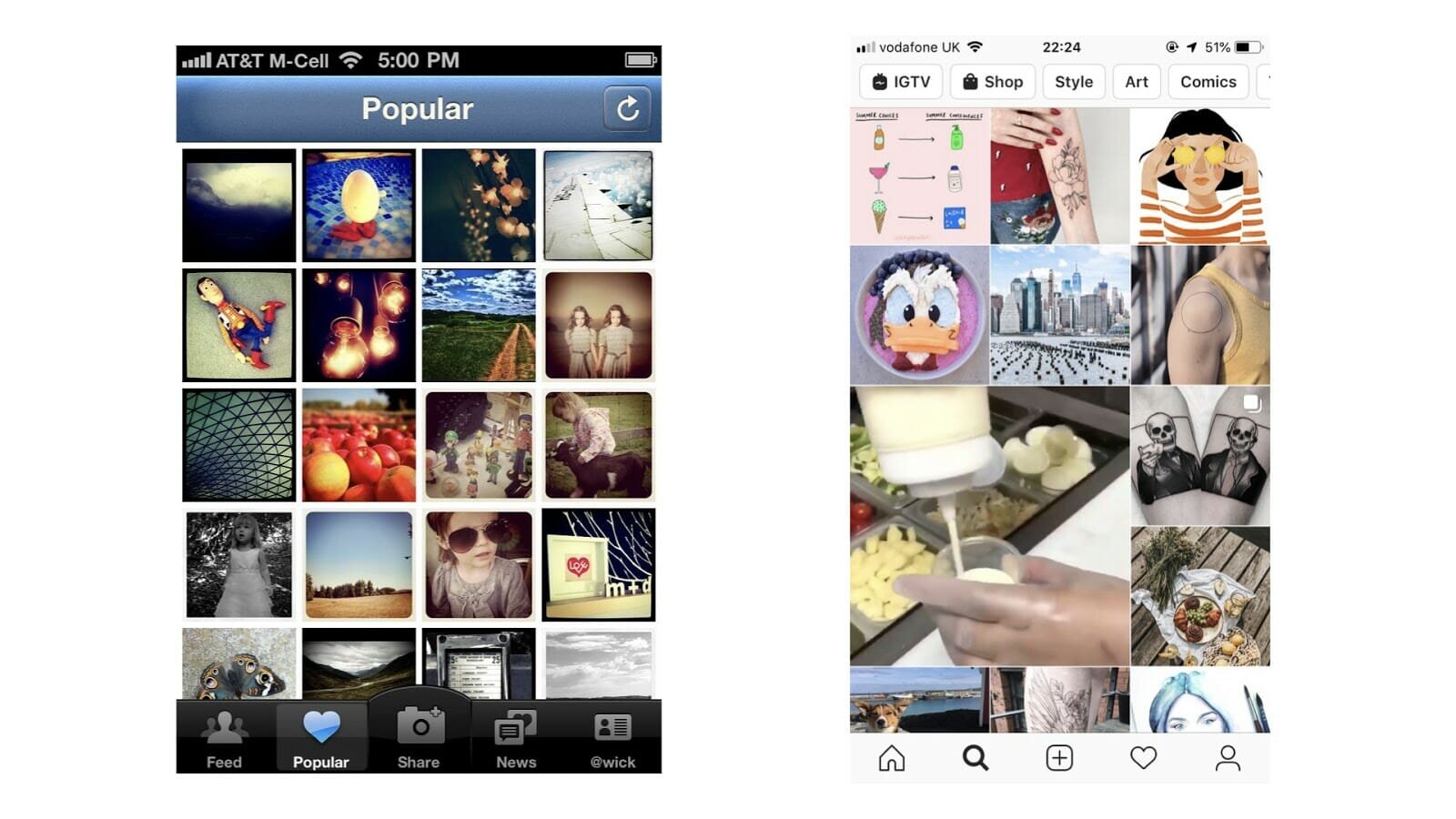
It’s actually a great way to think about a zero state for your product. Data takes time to collect but it shouldn’t prevent you from launching your product. Take a look at the image below of Instagram in 2010. In the tab Popular there is no ML, it’s just a list of pictures sorted by overall popularity. Over time this feature evolved and turned into the Instagram Explore tab: through number of experiments engineers turned it into a personalised and exciting experience.
Lesson 3: Account for Model Mistakes and Biases
One of the key responsibilities of a product manager is to brainstorm how your model might fail, and how to mitigate it at an early stage. Fixing a bias in the model later on might be a more difficult and costly process.
Imagine that you want to build a ranking model for your e-commerce website. Your website is super popular so you take just the last couple of months to train a model. You forget that your dataset also includes December and Christmas holidays that skew your data due to unusual user activity and behaviour. A mitigation in this case might be to use a wider time range to train the model.
As another example, imagine you’d like to build a model that would predict good candidates in tech based on their resume. You train your model on 10 years of data, and it shows good results before you realise that it has a strong gender bias that reflects male dominance in the industry. How could you have addressed it before training the model? If you had enough data for both genders, probably sampling would help. If there is not enough data, the key mitigation you can apply is simply not to build the model as its predictions will be biased.
While in the first example this mistake would simply lead to less relevant results and a lower conversion rate, in the second case it might cause bad decisions. That’s why it’s important to at least try and open the ML “black box” to people so they can understand what is happening and counter react. Explaining to users how the ML-driven product works not only gives them more confidence in the system but also allows them to better understand what is and what is not the expected behaviour that, in turn, will make the quality of our product better.
To be honest, opening the black box might be as complicated as building the model itself but the ML world is gradually changing this. For example, researchers from MIT recently announced the development of an interactive tool that lets users see and control how automated machine-learning systems work. So for a product manager it’s important to remember three things:
- If it’s possible, provide people with visibility into what’s happening.
- Provide people with a way to signal back and change the situation.
- If the consequences of the model failure can be neither fixed (as in the example with hiring) nor mitigated, it probably isn’t worth developing a model in the first place.
Lesson 4: Find Counter Metrics

The other side of people understanding how the model works is that they will try to game the system. For example, SEO is a way to “game” search algorithms and create content that would be shown on the first position in SERP.
What can we do about that? Let’s go one step back. When we first decide to build an ML-driven product, we start from the problem definition: in the case of Search it will probably be “users would like to be able to find relevant information on the internet quickly”. As ML requires something more specific and operational from us, we are trying to simplify this statement and understand what could quickly tell us if we got it right or wrong — for example, if a user clicked on a search result, they probably found it valuable. We are starting to optimise for click-through rates but soon enough see that users are starting to churn. Why is it happening? Some people learned that a sure way to get to the top of our Search is to create a clickbaity title and intriguing description so users would click on it but not find anything relevant. In our interpretation people clicking more is good but in reality they just can’t find what they are looking for. So we need to go back to our problem definition and think what defines “relevant information”.
- Is it something coming from a trustworthy source?
- Is the content original and unique?
- Does this page contain hundreds of pop ups? 🙂
- And so on
For Search we had to come up with a number of qualitative aspects that are constantly manually assessed and summed up in a score. These scores are used to evaluate the quality of a new model and compare it against our online wins. How do you identify qualitative aspects? It’s a combination of user research and expert consultation. Industry experts can provide you with the insights and domain knowledge that will help you come up with a v1, user research will help you stress test and refine those assumptions.
Another interesting aspect is that over time the system might start gaming itself. It’s called exploration/exploitation problem: if, for all your previous queries about “jaguars”, you clicked on links about cars, what should we show to you on the first position now – a page about the car or the animal? In most cases a good model would usually go for the former but who knows, probably you’ve never clicked on animals just because we’ve never showed them to you, not because you don’t like them. Randomisation and diversity are another two counter metrics you should be thinking about.

Lastly, just keep up to date. One of the key challenges for ML products is that they are a part of a living organism called your business, and they react sensitively to all changes. In most cases you are not creating a standalone ML model, you’re designing a feedback loop: if there are some changes to the interface, user action or data side, your model might change without you even noticing. Moreover, it’s not only changes in these components that might affect you. In 2006 Netflix organised a $1,000,000 competition to improve its recommendations: the goal was to improve the predictions of how many stars a user would give to a particular movie. The problem was very complex; the winning team had to combine 100 different algorithms and achieved fantastic accuracy, but the solution was never implemented. While the competition was running, the business changed: Netflix moved on to an online streaming model, and it became possible to collect user interactions like clicks or likes – this data was much better for recommendation engines. It became more important for a user to interact with a movie than to give it a high rating.
Lesson 5: Set Correct Expectations
In general, it seems like ML product development is not so different from the regular process: you identify the problem, size the opportunity, assess risks, measure the results and monitor regressions. On the other hand, the devil is always in the detail. In machine learning there are multiple moving parts and no universal solution, and it’s very unlikely that you will solve the problem at the first attempt. So one of the most important things that the ML product manager should do is set correct expectations. ML product development is not for sprinters, it’s for marathon runners. You can’t quickly hack a solution in two days as it’s continuous, exploratory and scrupulous work – and your teammates, external partners, and leadership should understand this. Here are a couple of recommendations for you:
- Clearly communicate the vision and the people problem you’re trying to solve. People often get lost when you’re going into too many technical details, keep it simple and high-level.
- If ML is a completely new area for your company, share the steps in the ML development process and where you've got to. Then it's easier for people to track your progress.
- Don’t commit to numeric goals at the start of the project: the whole is greater than the sum of its parts so you can’t evaluate the impact before you shipped your v1 model. Frame it as a learning opportunity, with clear definitions of success and failure.
For some people, machine learning is a maths problem; in my opinion, it’s a behavioural problem. Understanding human behaviours, emotions, decisions is never simple and takes time but, in return, you get an opportunity to build something truly unique. From designing objects and functions, we’ve moved on to design experiences and now, with ML technology, we are able to design the relationship between your user and your product. So don’t be afraid of the commitment: in the end, it’s the best path towards a happy and long product life.
Here are a few resources if you’d like to learn more about machine learning:
Courses:
- AI for Everyone (Coursera)
- Machine Learning (Stanford; Coursera)