
It takes many different competences to be a product manager, but one of the most important ones is the ability to decide on the future direction of your product. A product manager ideally uses a mix of methods to figure this out, with experiments at the forefront of strategic and meaningful decision-making.
The first real systematic experiment in medical history was carried out by James Lind in the 1700s, a time when sailors frequently suffered from scurvy. Lind chose to experiment with scurvy-struck sailors by giving them vinegar, seawater, cider, or fruit. After a week, the sailors who were given fruit were well enough to treat the others, and one was ready to work.
While the conclusion may seem pretty obvious with our present-day knowledge, it wasn’t so clear-cut that Lind could see it. It took him (and the rest of the world) decades to understand the problem and create a lasting solution – even after running a successful experiment.
He was faced with a challenge that still exists at the very core of product management today: how to interpret experiment results correctly. While this sounds like it should be straightforward, it actually requires the highest level of skill a product manager can have.
Let’s take a deeper look at why this is such an essential competence for product managers to possess and why it often goes so very wrong.
How to Evaluate Classic Split Testing
A big trap for any product manager is that they can forget to dig into the details of experiment results. While a simple A/B test (the color of a button for example) is often easy to evaluate, details become incredibly important as soon as a split test can have more than one effect. We can refer to these kind of tests as multivariate split tests because we compare more than one variable, and in my experience, most experiments are in fact multivariate experiments.
Let’s look at examples from online review site Trustpilot, where I used to lead the consumer site. Trustpilot wanted to switch over to a lighter colored design, so we looked into changing the header background color from black to white:
Old header:

New header:

While the objective was to get a lighter design, we still wanted to make sure that the header was providing us with the same value (all numbers needed to stay the same), i.e. searches and clicks on Categories, Log in, Sign up, and "For companies".
Variables measured:

We ran this split test on more than a million users (more than 500,000 users per variation). The overall results were:
| Improvement | All |
| For companies | 12% |
| Searches | -2% |
| Login | -1% |
| Signup | -2% |
| Categories | -7% |
The numbers are not exactly surprising. The elements that have become less prominently visible in the light design are also clicked on less: Categories, Logins, Signups and Searches all dropped.
Or did they?
We actually can’t say that. And if a product manager says this, you should immediately question their skillset. Because if we checked for statistical significance, then the percentage changes in Logins, Signups and Searches were not significant and therefore should be considered the same.
| All | |
| For companies | 12% |
| Searches | Same |
| Login | Same |
| Signup | Same |
| Categories | -7% |
Which means that Categories drops and For Companies increases in the lighter design. For Companies is Trustpilot’s entry for businesses to sign up, which makes it a direct way to get leads and therefore revenue. So it can be very tempting to jump to “We should implement this. We lose some category visits, but win more leads.” This is where you need to dive into the data. Because a deeper dive into devices shows a completely different picture:
| All | Mobile | Desktop | |
| For companies | 12% | -11% | 17% |
| Searches | Same | Same | Same |
| Login | Same | Same | Same |
| Signup | Same | Same | Same |
| Categories | -7% | -14% | Same |
Suddenly things have become much more complicated, because on mobile it looks like there are only negative effects. The extra details have made it difficult to interpret this simple test. Here are just a few things the product manager suddenly needs to consider:
- What are future trends? Will the number of people using mobile increase in the future? In Trustpilot’s case, mobile use grew from 37% in 2016 to 51% in 2018. So if this trend keeps up it will quickly become less attractive over time.
- What is the value of specific elements on the site? For Companies goes up, but is it really so much more valuable than when users go to Categories?
- Are we looking at different user segments here? Maybe some segments are using mobile phones more, while other segments are on desktop? In Trustpilot’s case, most business users were using desktop computers.
Taking all of these contradictory trends and numbers into account, what would you do? Well, deciding what to do in these cases is the product manager’s job. And if they quickly jump to conclusions with no deeper understanding and analysis of even a simple experiment, then they’re doing a poor job.
Evaluation of Data Enrichment: Trends in Numbers
Not all experiments are split tests. Another type of experiment is what is in medical science referred to as an A-B single-subject experimental design (this is not the A/B test you usually read about). This is where you give a treatment to see if the subject gets better, but only after establishing a baseline.
At Trustpilot, reviews for a company are shown on a company’s “profile page”. If a company does not have any reviews, there is only an empty profile page. Getting the first review is important for Trustpilot. It would be overwhelming and impossible to search if all non-reviewed companies in the world were shown, so an empty profile is only created when a user types in a specific company domain. The name of the company is then the name of the domain. In order for Trustpilot to get more valuable first reviews, Trustpilot wanted to know if enriching empty profiles with the real name, address, and description would make more users write first reviews. It seemed like an obvious thing to do, because companies were automatically assigned a domain name which in many cases made little sense. For example: Dusseldorf Airport was called DUS (domain: dus.com). This is (with good reason) very difficult to understand for most users. Especially users searching for Dusseldorf Airport:
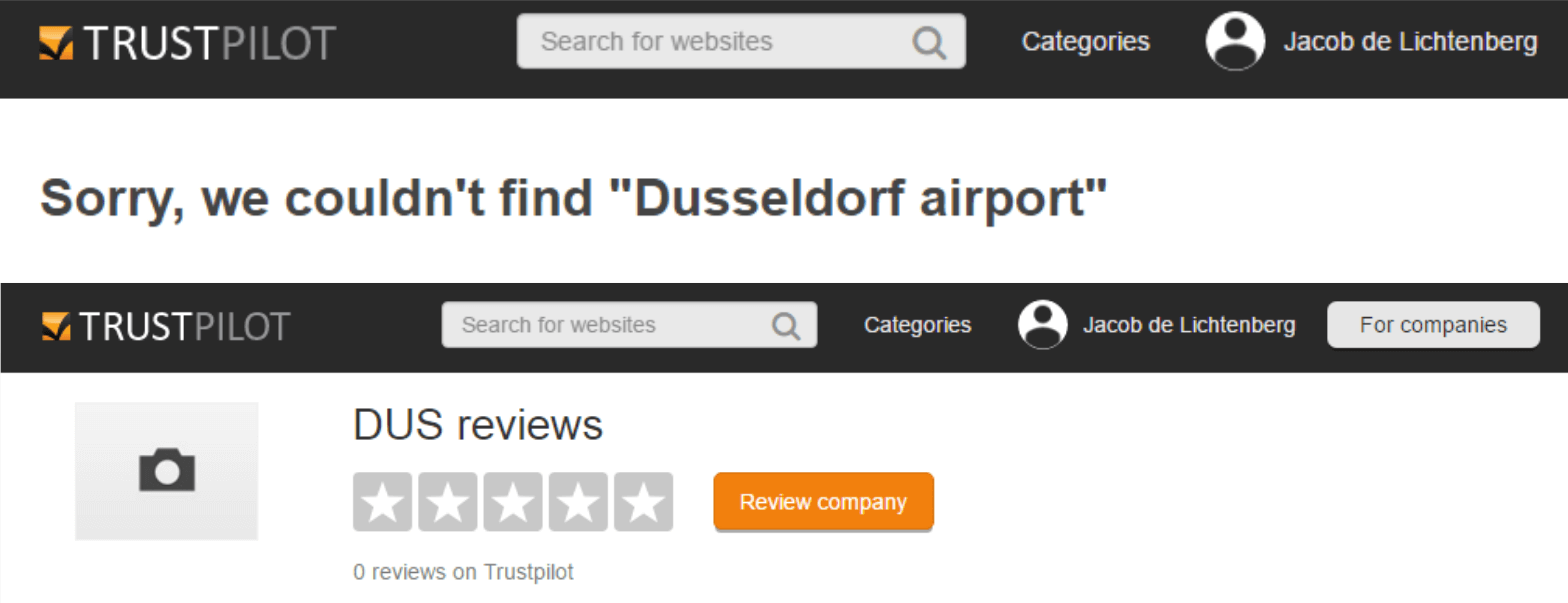
Users would more easily find companies if we added the real company name, description, and address to their profile. While it might be an obvious thing to do, it didn’t come for free. Trustpilot would have to pay a third-party vendor for the information, so we needed to find out if doing this was going to be valuable enough. We ended up measuring this by looking at when companies received their first review in order to see if more new companies were reviewed because they were more easily found:
| Weekly Average: Number of first reviews | |
| Nov-Dec | 909 |
| Feb-Mar | 1030 |
| Improvement | 13% |
The results looked pretty amazing after just five months. In a perfect world we would have “stopped the treatment” to see if the numbers dropped again in an A-B-A experiment design. I can hear you already – what company would ever remove anything that looked like a success?
Which meant that we had to look at and interpret the results in another way. We ended up comparing them to similar numbers outside the experiment (as you would do in any other experiment). In this case, we looked at the total number of reviews in the same period:
| Weekly Average: Number of total reviews | |
| Nov-Dec | 199.986 |
| Feb-Mar/td> | 215.858 |
| Improvement | 8% |
Comparing the results to the general trend in numbers made them look a lot less sexy. Again, it's part of the product manager’s job to look at this value over the cost of buying the data. But if the product manager hasn’t looked at data outside the single-subject experiment, then you should consider the data to be useless. Comparing results to numbers outside the experiment often alters interpretations, which may have a huge impact on your decision-making.
Evaluating a new Feature: Measuring Right
The decision to build a new feature typically entails competitor analysis, strategic thinking, customer insight, and finally, experiments. It would of course be nice to have the opportunity to talk to your customers to see if they are even interested in buying or using a new feature, but nothing beats real behavioral data. In other words: if we build it, will the user actually use it?
Let’s look at another example from Trustpilot. Trustpilot’s compliance department was spending 20% of its time on defamatory statement tickets. This is when users write reputation damaging reviews without evidence to back it up, or when they write humiliating language without cause. Here are two examples:
| Defamatory statement:
|
Coarse language:
|
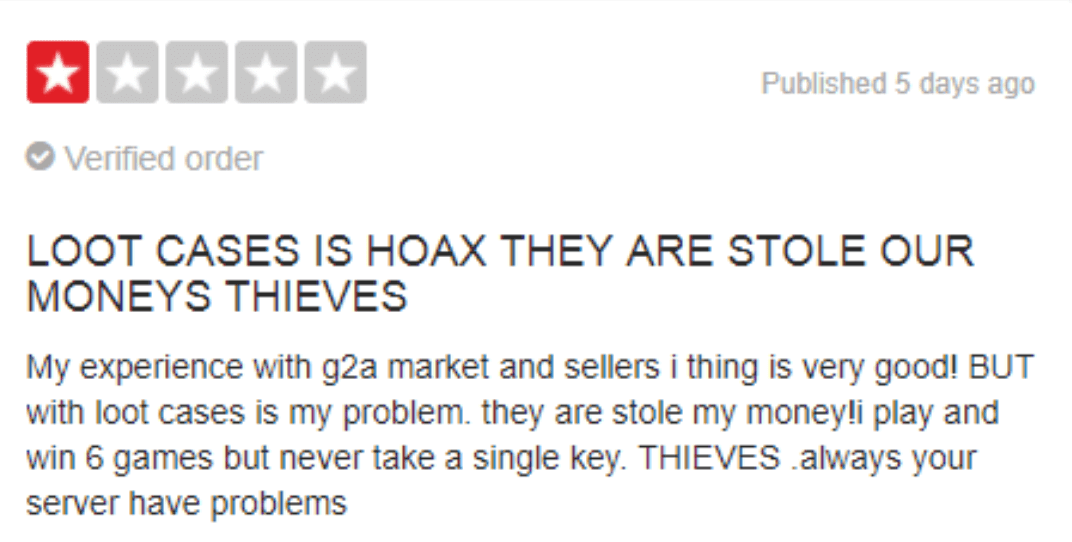
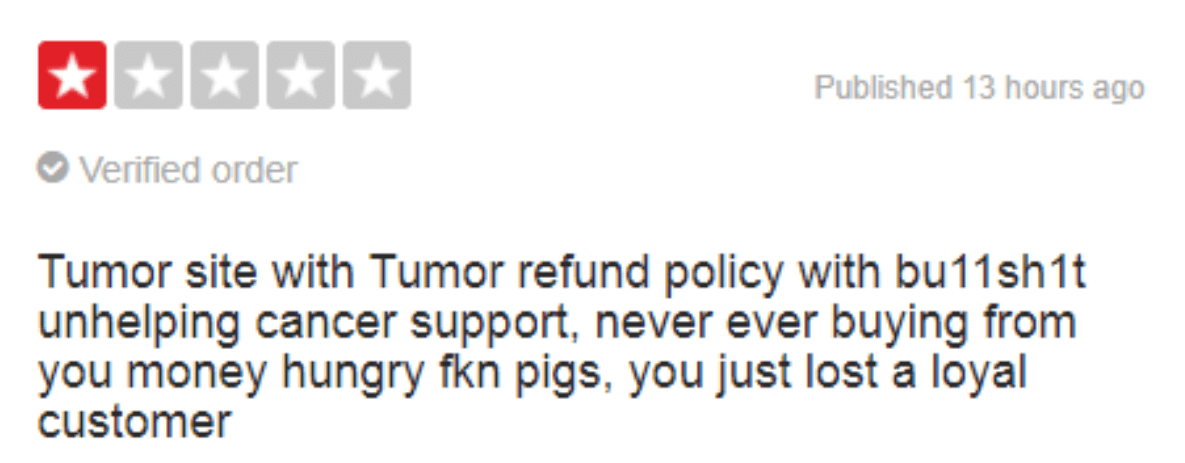
These types of reviews could actually be really valuable for other users. Another user would find it much more useful if the reviewer explained why they lost their money, instead of just calling the company scammers or thieves without any explanation.
To see if real value could be extracted from these kind of reviews, Trustpilot began to highlight words that are typically considered defamatory:
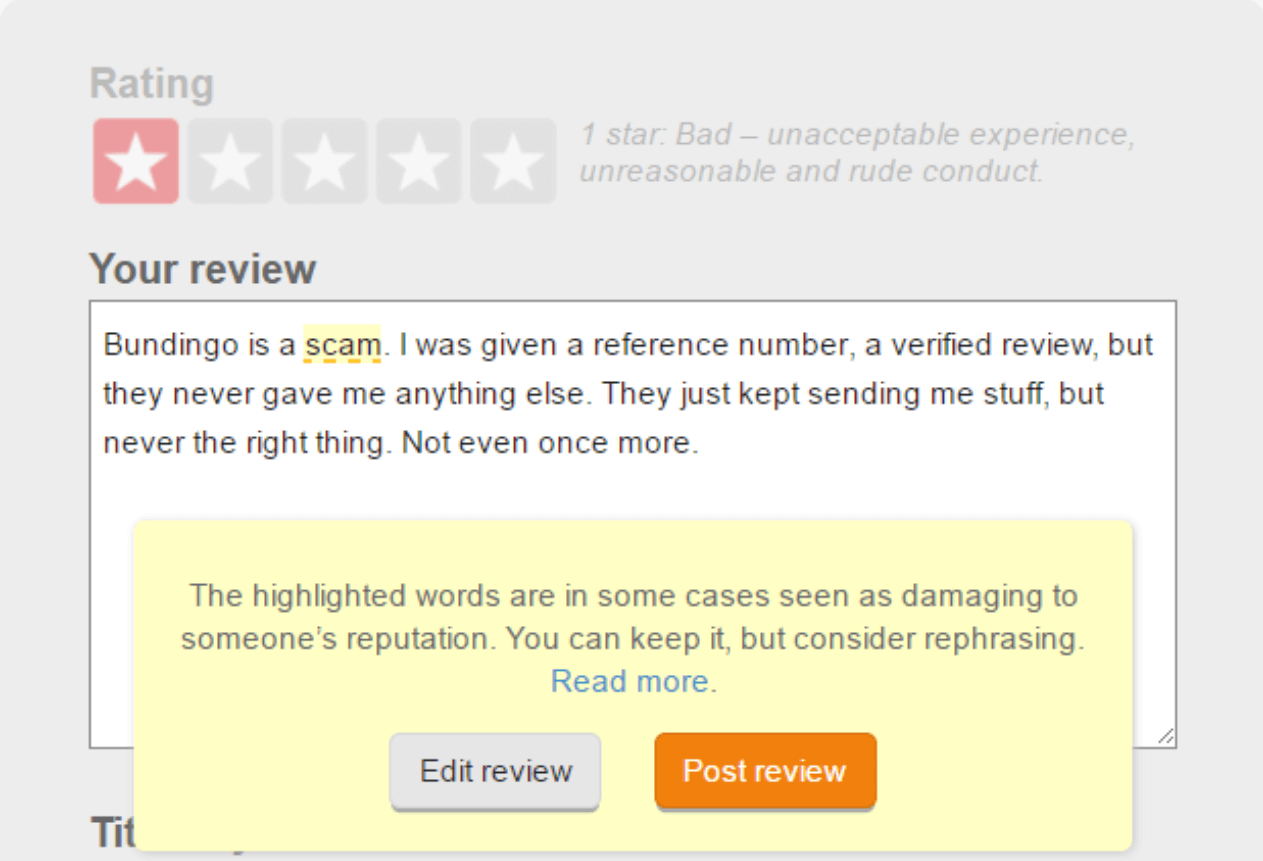
The result? A whopping 44% chose to click on the button Edit review. If we took this result at face value we’d be able to reduce the workload of our compliance department by 9% (44% x 20%) which would be a huge relief for them. Again, the results seem pretty clear cut, but only if you choose not to dig deeper. Because clicking a button doesn’t really measure if people stopped writing defamatory statements. It was a quick way to learn something new, but it provided too little information to be able to make a final decision. So we ran an additional experiment where we recorded what users did after they clicked on Edit review.
From those recordings it turned out that only 16% actually changed their review to something that was no longer defamatory. Many users simply changed their wording to something that was equally defamatory.
We decided to bring these two experiments together in order to get a more precise result. All of a sudden the end results turned out to be a 1% (44% x 20% x 16%) decrease in workload for the compliance agents. Looking at the workload it would take to build this, the final decision was now very different.
Evaluating a new Feature: Mixed Results
There are a multitude of things you can do to evaluate whether you should build a new feature. But you can’t do all of them (as much as you would like to). So often we ask ourselves what our most risky assumptions are, and then we simply test these. At Trustpilot we wanted to know if we should build a Q&A feature where everyone could ask and answer questions about a company. We believed it could turn out to be a great feature for our community, but we’d also seen this type of feature go completely unused on other websites. While we had many assumptions, our most risky assumption was whether users would ask any questions in the first place. In order to test this, we made a fake door test where users could ask questions:
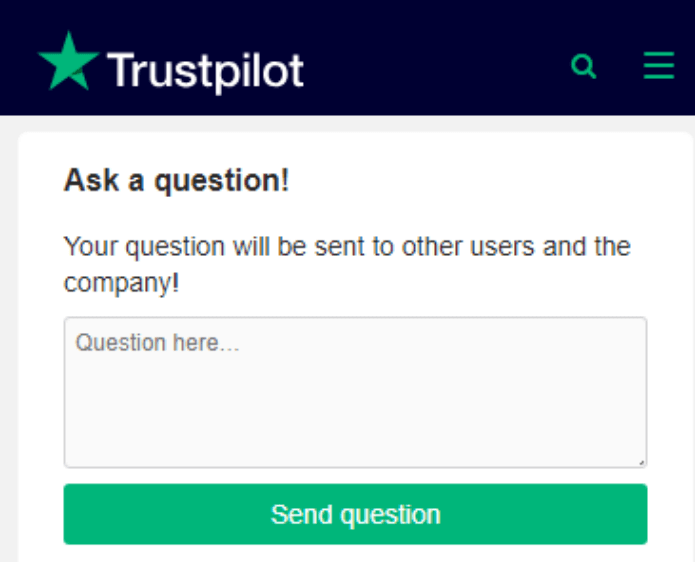 |
 |
Our OKR objective was to increase engagement on the site by 40% in order to let people help each other more. Therefore we defined engagement as any type of interaction that created content; asking questions, answering questions and writing reviews. After we added the feature we could see the following results:
| Increase in engagement |
| 11% |
We then checked for significance, devices, countries, and user trends, and found this result:
| Increase in engagement | |
| Mobile | Desktop |
| 17% | 4% |
After this, we discussed if we were really measuring the users who were asking questions here. We needed more information. In order to figure that out we had to go through 400 actual questions. As it turned out, around 30% of users wrote things that were not questions, e.g. “Still waiting”, “I used this company for an event and they were amazing,” “Thank you”, “How do you live with yourself”. This changed the numbers quite drastically:
| Increase in engagement | ||
| Mobile | Desktop | |
| Sends questions | 17% | 4% |
| Actual questions | 12% | 3% |
The results for mobile are the most interesting since we know mobile usage will continue to increase immensely. But with an objective of a 40% increase in engagement, and the test only showing a 12% increase on mobile (and less on desktop), it was time to discuss once again if this feature would be meaningful for us to pursue at all.
As people answering questions also falls under the category of engagement, this brought us to our next-level assumption: if we assume that all questions receive one answer, then engagement on mobile will increase by 24%. With that assumption in mind, it would be a natural next step to test if it was in fact true. There was of course also the possibility of one question receiving multiple answers, which would allow us to reach 40% on mobile.
This is also an obvious place where the product manager really needs to step up. If we'd had astonishing results showing an 50% increase in engagement only from questions, it would probably have been an easy decision to make. But now the product manager needs to consider the strategic benefits of the feature, understand the background of why the objective is 40% and not another number, and include everything they can from the company’s business model.
For the purposes of this article I’ve decided not to go into things like feasibility and the efforts required to build a feature. But both these aspects play an extremely important role in the decision-making process as well.
Just consider the following questions in relation the last feature example:. How difficult is it to develop a Q&A feature? Will it have any downstream effects for the organization? How do we handle the 30% input that are not questions? Are there any legal problems? How can we handle the compliance part of users misusing a question and answer option? How will companies react to unpleasant questions?
And all of these considerations are just for this one Q&A feature idea. It’s likely there are multiple other ideas in Trustpilot for how to increase engagement that might have better value with the exact same effort. These are all things a product manager needs to keep in mind (and discuss with others) to avoid making bad decisions.
Checklist for Evaluating Experiments
Below is an incomplete checklist of things I think product managers need to keep in mind when evaluating experiments:
- Never go with your gut. Multiple cognitive biases will trick you into fulfilling your hopes.
- Check for statistical significance first (take care not to make premature conclusions!)
- Evaluate all device families/screen sizes. Remember that something as simple as Mac vs. PC and iPhone vs. Android use different design patterns – for example, nobody agrees on what a sharing icon should look like.
- Evaluate all countries. There are multiple reasons for this, for example, some things are understood differently in other cultures. Translations can also cause problems. Sometimes, German and Dutch have very long words that break designs/UI, which may explain weird experiment results.
- Consider and analyze different segments/cohorts. Your users might act differently based on the job they are trying to do.
- Look at the actual numbers and not only percentages. “10% increase” may sound cool, but this could be 10 to 11.
- Consider user trends before deciding. What will these results be like one or two years from now? For example, is the mobile proportion still increasing/as relevant as it is today?
- Look at external trends that could be having an impact on the numbers in your experiments. For example, maybe the numbers just went up because of Christmas sales.
- Measure twice, cut once: remember to discuss how close to the actual end result you are measuring. When running discovery experiments we often do not measure the actual end result. Rather we’re attempting to simulate something to learn new things fast. But when making decisions you need to include exactly where you need to go in your discussions.
- Is a second experiment necessary? Maybe the result of your experiment is that you just learned something you didn’t think of, and now you need to run an additional experiment.This happens pretty often.
- Have a colleague look at the results to avoid your own bias. Similar to developers’ code reviews, there should be an experimental result review.
- Think about the company-wide costs involved (not just the development and general maintenance costs). What happens with your experiment downstream? Will any other departments be impacted by these experiments and decisions?
- Consider if the results will take the company in the direction of the strategy. The product manager needs to have detailed knowledge of the strategy. That’s why you have a product manager in place to begin with.